





Understanding the Critical Link Between Cloud Computing and Disaster Recovery
Cloud computing and disaster recovery are essential technologies that work together to ensure business continuity in the face of disruptions. For businesses seeking to protect their critical data and systems, here’s what you need to know:
| Cloud Disaster Recovery Essentials | Description |
|---|---|
| Definition | Using cloud resources to back up data, applications, and infrastructure to restore operations after a disruptive event |
| Key Benefits | Cost efficiency, scalability, geographic redundancy, reduced recovery time |
| Common Approaches | Cold DR (lowest cost), Warm DR (balanced), Hot DR (fastest recovery) |
| Critical Metrics | Recovery Time Objective (RTO): how quickly systems must be restored Recovery Point Objective (RPO): acceptable data loss timeframe |
| Statistics | 44% of organizations experience major outages, often from power failures |
In today’s digital landscape, disasters come in many forms – from natural events like floods and fires to human-caused disruptions like cyberattacks and system failures. When these events occur, the consequences can be devastating. According to research, nearly half of businesses that suffer major data loss shut down permanently, with data loss in the US alone costing businesses over $11 billion annually.
Traditional disaster recovery methods often required duplicate hardware, dedicated facilities, and complex maintenance – putting effective solutions out of reach for many small and medium businesses. However, cloud computing and disaster recovery solutions have revolutionized this approach, making enterprise-grade protection accessible to organizations of all sizes.
Cloud-based disaster recovery shifts the focus from expensive hardware investments to flexible, scalable services that can be rapidly deployed when needed. This approach transforms disaster recovery from a capital expense to an operational one, allowing businesses to pay only for what they use while still maintaining robust protection.
I’m Paul Nebb, founder of Titan Technologies, and I’ve spent over a decade helping businesses implement effective cloud computing and disaster recovery solutions that protect their critical data and ensure operational continuity even during the most challenging circumstances.

Cloud computing and disaster recovery further reading:
– aws dr solutions
– backup and dr solutions
– disaster recovery plan example
The High Stakes of Digital Outages
When it comes to business continuity, the stakes couldn’t be higher. A significant outage doesn’t just mean temporary inconvenience—it can threaten your organization’s very existence. Consider these sobering realities:
- Financial Impact: Downtime costs vary by industry and company size, but even for small businesses in New Jersey, the cost can be thousands per hour when you factor in lost productivity, revenue, and recovery expenses.
- Compliance Consequences: In many regions, data privacy laws require disaster recovery plans to protect sensitive data. Failure to quickly recover after a disaster can lead to compliance violations and substantial fines.
- Reputational Damage: Perhaps most devastating is the long-term impact on customer trust. When clients in Princeton or Newark can’t access your services or their data is compromised, that relationship damage may never fully heal.
As we’ve seen with clients across Central New Jersey, from healthcare providers in New Brunswick to financial services firms in Trenton, the ability to quickly restore operations isn’t just a technical consideration—it’s a business imperative.
Why Disaster Recovery Matters: RTO & RPO Basics
When it comes to protecting your business, understanding disaster recovery isn’t just about having backups—it’s about knowing how quickly you need to be back up and running, and how much data you can afford to lose if disaster strikes. Let’s break down these crucial concepts in simple terms.
Recovery Time Objective (RTO) is essentially your answer to “How long can we survive without our systems?” For a retail business during the holiday season, this might be measured in minutes. For your accounting department during a slow period, perhaps days are acceptable. Your RTO determines how quickly your recovery solution needs to spring into action.
Recovery Point Objective (RPO) answers a different but equally important question: “How much data are we willing to lose forever?” If you back up every 24 hours, you’re essentially saying you can live with losing up to a day’s worth of data. For some businesses, that’s fine. For others, even minutes of lost transactions could be catastrophic.
| System Type | Typical RTO | Typical RPO | Business Impact |
|---|---|---|---|
| Mission-critical (e.g., payment processing) | Minutes | Seconds to minutes | Severe revenue loss, regulatory issues |
| Business-critical (e.g., CRM systems) | Hours | Hours | Significant operational disruption |
| Non-critical (e.g., internal knowledge bases) | Days | 24 hours | Limited operational impact |
Here at Titan Technologies, we’ve helped businesses throughout Central New Jersey—from busy Elizabeth to coastal Red Bank—conduct thorough business impact analyses. This isn’t just a technical exercise; it’s about understanding what makes your business tick and what would make it stop ticking in a crisis.
Understanding Cloud Computing and Disaster Recovery Metrics
Beyond the fundamental RTO and RPO metrics, cloud computing and disaster recovery planning involves categorizing your systems into recovery tiers based on their importance to your business:
Recovery Tier 0 systems simply cannot go down—think hospital emergency room systems or financial trading platforms where minutes of downtime mean serious consequences.
Recovery Tier 1 includes your business-critical applications that can tolerate brief outages measured in hours, but not much more.
Recovery Tier 2 systems are important but can be offline for up to a day without catastrophic business impact.
Recovery Tier 3 comprises systems that, while valuable, could be unavailable for several days if necessary.
For our clients in places like Woodbridge and Freehold, we don’t just look at technical specifications when determining these tiers. We consider the real business factors: Will you lose revenue? Will customers notice? Are there compliance concerns? Do other systems depend on this one? Does it matter more during certain times of year?
This human-centered approach ensures your cloud computing and disaster recovery strategy isn’t just technically sound—it’s aligned with what your business actually needs to survive and thrive, even when the unexpected happens.
Cloud Computing and Disaster Recovery: Benefits & Challenges
When we talk with our clients about cloud computing and disaster recovery, their eyes often light up once they understand the game-changing benefits this combination offers. Gone are the days of maintaining expensive “just in case” infrastructure that sits idle most of the time.
The beauty of cloud-based DR lies in its elasticity – you can scale resources up only when needed. For our small business clients in Matawan, this means they’re not burning cash on computing power that’s used only during emergencies or testing. This flexibility transforms disaster recovery from a financial burden into a strategic advantage.
The pay-as-you-go economics of cloud DR has been particularly transformative for our clients in Lakewood and Edison. Rather than making massive upfront investments in hardware that starts depreciating the moment it’s installed, they now enjoy predictable monthly expenses that can be classified as operational costs. This shift frees up capital for growth initiatives while still maintaining robust protection.
Perhaps most impressive is the geographic redundancy that cloud providers offer. With data centers scattered across the globe, your backups can reside continents away from your primary infrastructure – a level of separation that would be financially impossible for most businesses to achieve on their own. When a client in Newark worries about regional disasters, we can confidently design solutions that distribute their recovery capabilities across multiple geographic zones.
The power of automation in cloud environments can’t be overstated either. Modern cloud platforms provide sophisticated tools that can orchestrate complex recovery procedures with minimal human intervention. This not only reduces recovery time but also eliminates the possibility of those pesky human errors that tend to crop up during stressful disaster scenarios.
Of course, cloud computing and disaster recovery isn’t all sunshine and rainbows. We’re always transparent with our clients about the challenges they might face:
Vendor lock-in concerns are real. Becoming too dependent on a single cloud provider’s proprietary services can make changing providers later feel like trying to escape a technology quicksand. We help clients balance proprietary features with portability considerations.
During widespread disasters, connectivity risks become apparent. Cloud DR depends on internet access, which might be compromised during major events. For critical systems, we often recommend hybrid approaches that maintain some local recovery capabilities.
The complexity of cloud environments can catch organizations off-guard. What looks simple in a sales demo often requires specialized knowledge to implement correctly. Our team stays continuously trained on the latest cloud technologies to steer these complexities for our clients.
And let’s not forget about those sneaky data transfer costs. Moving large volumes of data to and from the cloud can trigger significant bandwidth charges, especially during recovery operations. We always build these considerations into our planning process.
For those interested in the latest research on this topic, this comprehensive guide on information security provides valuable context on how disaster recovery fits into broader security frameworks.
How the Cloud Changes Traditional DR
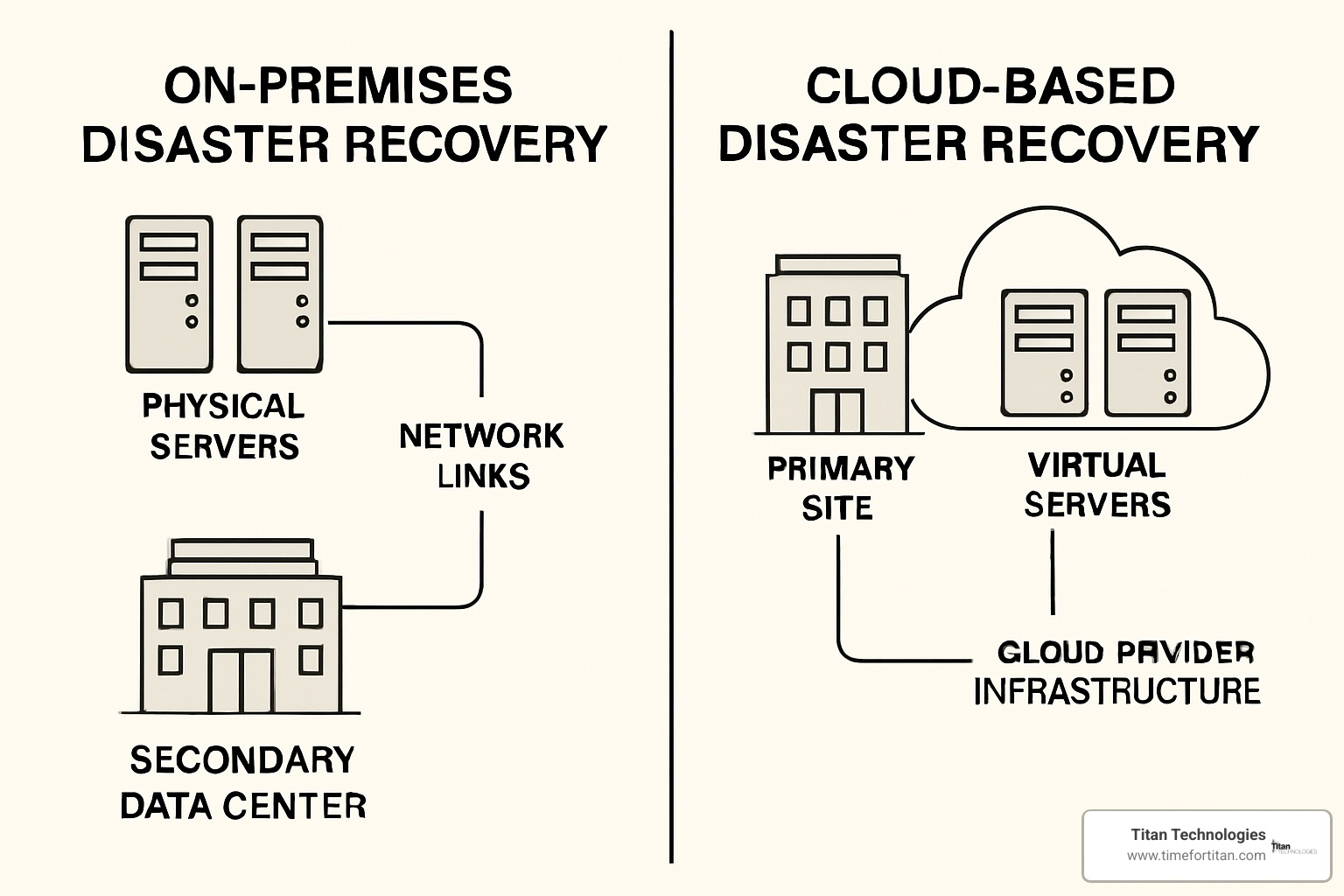
The shift to cloud computing and disaster recovery represents nothing short of a revolution in how businesses approach resilience. When I explain this to clients across Central New Jersey, I often use the analogy of moving from owning a vacation home (that sits empty most of the year) to booking a hotel room only when you need it.
Traditional DR required significant upfront investment in duplicate infrastructure – a capital expenditure approach that put robust disaster recovery out of reach for many small and medium businesses. Cloud DR converts this to predictable monthly expenses that can be treated as operational costs, making enterprise-grade protection accessible to organizations of all sizes.
The move from physical to virtual infrastructure has been equally transformative. Rather than maintaining physical servers gathering dust in a secondary location, cloud DR leverages virtual machines that exist only when needed. This approach eliminates hardware maintenance headaches and ensures your recovery environment always runs the latest configurations.
Cloud providers offer multiple regions worldwide, providing unprecedented global reach compared to the single backup site limitation of traditional approaches. For a business in Princeton, this means your recovery site could be in Oregon, Ireland, or Singapore – far beyond the reach of whatever regional disaster might affect the Northeast.
Perhaps most exciting is the shift from manual to automated recovery. Traditional DR often involved thick binders of procedures and human coordination prone to error. Cloud DR enables automated failover and recovery orchestration that can be tested regularly without disruption. One of our clients in Elizabeth reduced their recovery time from 18 hours to just 35 minutes through automation.
The ability to scale resources dynamically based on actual needs – moving from fixed capacity to elastic scaling – means you’re not paying for peak capacity that sits idle most of the time. This approach aligns perfectly with modern business needs for efficiency and cost optimization.
Key Challenges to Address
Successfully implementing cloud computing and disaster recovery requires addressing several key challenges head-on. We’ve guided countless businesses through these waters, and here’s what we’ve learned:
Latency considerations are critical, especially for performance-sensitive applications. The physical distance between your primary site in New Brunswick and a cloud recovery location in California can introduce delays that impact user experience. We carefully assess application requirements to ensure acceptable performance, sometimes recommending multi-region approaches for the most sensitive workloads.
Security in cloud environments requires a different mindset than on-premises infrastructure. Data must be encrypted both in transit and at rest, with proper access controls and authentication mechanisms. We implement zero-trust security models that verify every access attempt, regardless of where it originates.
For clients in regulated industries like healthcare and finance, compliance requirements add another layer of complexity. We work closely with organizations to ensure their cloud DR solutions meet HIPAA, PCI, and other relevant standards, maintaining proper documentation for auditors.
Cloud provider Service Level Agreements (SLAs) often contain nuances that can surprise the unprepared. We help clients understand both the guarantees and limitations of their cloud DR services, sometimes supplementing with additional protections where critical gaps exist.
Those seemingly innocent egress fees can become budget-busters during actual recovery operations. While storing data in the cloud is relatively inexpensive, retrieving large volumes during recovery can trigger significant data transfer charges. Our planning process includes detailed cost modeling for various recovery scenarios to avoid unpleasant surprises.
At Titan Technologies, we believe that understanding these challenges is the first step toward building a resilient cloud DR strategy that truly protects your business when disaster strikes.
Strategy Spectrum: Cold, Warm, Hot & Beyond
When it comes to cloud computing and disaster recovery, not all strategies are created equal. Think of these options as existing on a spectrum—from basic protection that’s light on the wallet to premium solutions that get you back up and running almost instantly.
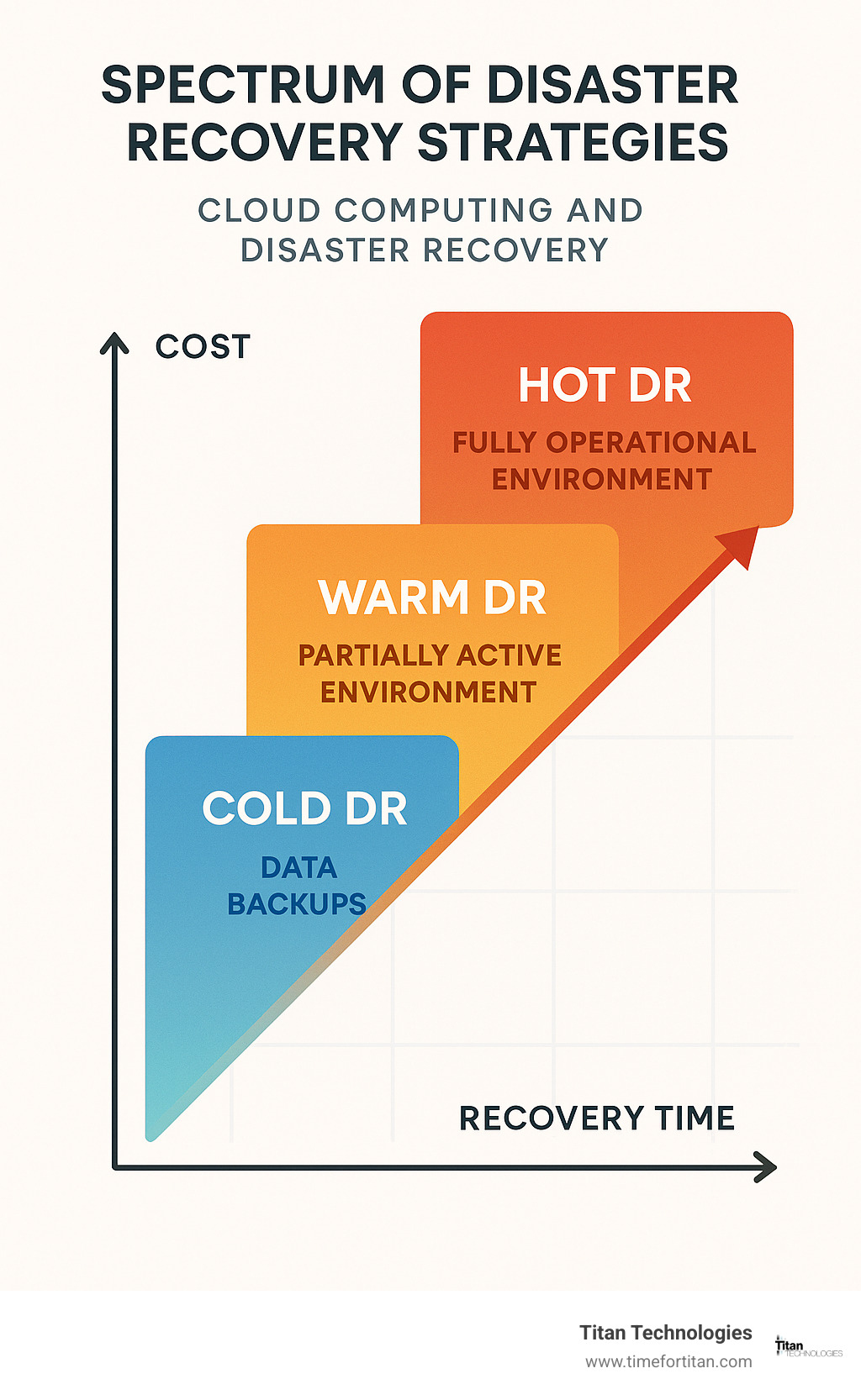
Cold DR is like having your winter clothes packed away in storage. You’re only keeping data backups in the cloud, with no servers running until you need them. When disaster strikes, you’ll need to set up your servers from scratch, install all your applications, and then restore your data. It’s definitely the budget-friendly option, but recovery could take anywhere from several hours to days. For many of our smaller clients in Central New Jersey, this approach makes sense for non-critical systems.
Moving up the scale, Warm DR offers a happy medium. Here, you maintain a scaled-down version of your environment in the cloud—the applications are installed and ready, but not actively running. When trouble hits, you simply scale up your resources and restore your most recent data. Most of our clients in places like Edison and Woodbridge find this “Goldilocks” approach gives them the right balance of cost and speed, with recovery typically taking minutes to hours.
For those mission-critical systems that simply can’t be down, Hot DR is the premium solution. This approach maintains a fully operational duplicate environment in the cloud that’s continuously receiving data updates from your production systems. When disaster strikes, you just redirect traffic to your cloud environment and—voilà!—you’re back in business within minutes or even seconds. Yes, it costs more, but for our healthcare clients in Newark or financial services firms in Red Bank, that peace of mind is worth every penny.
Many businesses also consider these specialized approaches:
Pilot Light keeps just the essential core components (typically your databases) running while everything else remains dormant until needed. It’s like having the pilot light on your furnace—ready to fire up the whole system quickly when needed.
Multi-site Active/Active is the Fort Knox of disaster recovery. Your workloads run simultaneously across multiple locations, so if one site goes down, the others keep humming along without missing a beat. Your users might not even notice anything happened!
Most of our clients across New Jersey benefit from Hybrid Approaches—using hot DR for their can’t-be-down systems while choosing warm or cold DR for less critical applications. This smart mixing of strategies gives you the best protection where you need it most without breaking the bank.
I always recommend considering Immutable Backups as part of any strategy. These special backups can’t be altered or deleted once created—even by administrators—providing crucial protection against ransomware attacks. When cybercriminals try to hold your data hostage, you can simply say “no thanks” and restore from your untouchable backups.
Cloud Computing and Disaster Recovery in Action
Let me share some real-world examples that show how cloud computing and disaster recovery solutions have saved the day for our clients:
A manufacturing client in Elizabeth found themselves staring at ransomware screens one Monday morning. Instead of panic, they called us with confidence. Thanks to their cloud-based immutable backups, we restored their operations within hours, losing only about 15 minutes of transaction data. No ransom paid, minimal disruption, and a very relieved CEO.
Nasty storm that knocked out power across half of New Jersey last year? A financial services firm in Red Bank barely noticed. Their systems seamlessly failed over to their cloud environment in another region, and their customers continued making transactions without interruption. The firm’s competitors were down for days, while our client didn’t miss a beat.
When a critical database server decided to call it quits at a healthcare provider in Newark, their warm DR setup allowed us to activate cloud resources and restore service well within their 4-hour recovery window. Not only did they maintain patient care, but they also stayed compliant with those strict healthcare regulations.
One of my favorite success stories comes from a retail client in Trenton who regularly tests their DR capabilities by spinning up a complete duplicate environment in the cloud—something that would cost a fortune with traditional disaster recovery approaches. This regular testing meant that when they actually faced a crisis, their team executed the recovery with confidence and precision.
AWS, Azure, Google Cloud Toolkits
The major cloud providers offer powerful tools to implement your cloud computing and disaster recovery strategy:
AWS Elastic Disaster Recovery (formerly known as CloudEndure) continuously replicates your machines into a staging area in your AWS account. When disaster strikes (or during a planned drill), you can quickly launch thousands of machines in their fully provisioned state within minutes. For our clients with complex environments, this service has been a game-changer.
Azure Site Recovery orchestrates the replication, failover, and recovery of your workloads so they’re available from a secondary location if your primary site goes down. It’s remarkably flexible, supporting various scenarios including Azure-to-Azure replication, VMware/physical server to Azure, and Hyper-V to Azure. Several of our clients in Princeton have found this Microsoft solution integrates perfectly with their existing environments.
Google Cloud Backup and DR provides centralized management for protecting your data and orchestrating recovery across hybrid and multi-cloud environments. Its policy-based management and automated testing ensure you’re always ready for the unexpected.
For businesses looking to improve their resilience planning, AWS offers the impressive AWS Resilience Hub, which helps assess and improve your application’s disaster recovery posture.
At Titan Technologies, we help businesses across Central New Jersey steer these options to find the right fit for their technical requirements and business objectives. The right solution isn’t always the most expensive one—it’s the one that aligns with your specific recovery needs and budget realities.
Building & Testing Your Cloud DR Plan
Let’s face it – having a plan is only valuable if it actually works when disaster strikes. That’s why building and regularly testing your cloud computing and disaster recovery plan isn’t just good practice – it’s essential for business survival.
Start with a thorough risk assessment that reflects your specific business reality. If you’re located in coastal areas like Red Bank, your risk profile looks quite different from businesses in urban centers like Newark. We’ve helped clients identify risks they never considered, from seasonal flooding patterns to infrastructure vulnerabilities specific to their neighborhoods.
Infrastructure as Code (IaC) has revolutionized how we approach disaster recovery. By defining your infrastructure using code – whether through AWS CloudFormation or Azure Resource Manager templates – you ensure consistent, repeatable deployments when you need them most. One of our manufacturing clients in Edison reduced their recovery time by 70% simply by implementing IaC principles.
The magic happens when you add orchestration and automation to the mix. Think of orchestration as the conductor ensuring all your systems recover in the right sequence, while automation eliminates those error-prone manual steps. Together, they transform recovery from a frantic scramble to a controlled, predictable process.
I’m a big fan of chaos engineering – it might sound counterintuitive, but deliberately breaking things in controlled environments helps identify weaknesses before real disasters strike. We recently helped a client in Woodbridge find a critical dependency they never documented until we simulated a failure scenario.
Don’t underestimate the value of good old-fashioned tabletop drills. Gathering your team around a table (virtual or physical) to talk through disaster scenarios helps identify gaps in your procedures and clarifies everyone’s roles when the pressure is on. These conversations often reveal assumptions that could prove problematic during an actual crisis.
Detailed documentation might not be glamorous, but it’s your lifeline during a disaster. When systems are down and stress levels are high, having clear, accessible recovery procedures makes all the difference. We recommend storing this documentation in multiple locations, including offline copies.
Remember – a cloud computing and disaster recovery plan is never “finished.” It should evolve as your business grows, technologies change, and new threats emerge. That’s why we work with our clients across Central New Jersey to regularly revisit and refine their plans.
Best Practices Checklist
Building a robust cloud computing and disaster recovery strategy isn’t about checking boxes, but there are some non-negotiable practices that set successful recoveries apart from failures:
Define clear roles and responsibilities so everyone knows exactly what they’re accountable for during a recovery situation. Include backup personnel for each critical function – emergencies don’t care if your primary IT person is on vacation.
Schedule regular testing at least annually and after any significant infrastructure changes. One of our clients in Matawan finded their backup system had been misconfigured for months, but only learned this during a scheduled test.
Implement versioned backups to protect against corrupted data or gradual corruption that might go undetected. We recommend following the 3-2-1 approach: three copies of your data, on two different media types, with one copy stored offsite.
Encrypt everything, both in transit and at rest. Data security doesn’t take a holiday during disasters – in fact, recovery periods often present heightened security risks as normal protections may be bypassed.
Document dependencies carefully so systems are recovered in the correct order. We’ve seen recovery efforts fail simply because applications were brought online before their supporting databases.
Your plan should be living and breathing – review and update regularly, train all personnel thoroughly, and create clear communication plans for both internal teams and external stakeholders.
Compliance & Regulatory Alignment
For many businesses in Central New Jersey, compliance considerations add another layer to cloud computing and disaster recovery planning. Healthcare organizations in New Brunswick must ensure HIPAA compliance, maintaining patient data protection with specific requirements for backup, recovery capabilities, and audit trails.
Financial services firms in Trenton steer complex regulatory frameworks that mandate specific recovery timeframes and data protection standards. GDPR requirements add further complexity for organizations handling EU citizen data, requiring the ability to restore access to personal data promptly following any incident.
Data sovereignty issues can significantly impact where your cloud backups are stored and processed. Some data must legally remain within specific geographic boundaries, which may limit your cloud provider options or require specialized configurations.
Don’t forget about documentation – maintaining evidence of regular testing and successful recovery operations isn’t just good practice, it’s often a compliance requirement. We help our clients develop documentation systems that satisfy even the most demanding auditors while actually being useful during real recovery scenarios.
At Titan Technologies, we work alongside compliance officers and legal teams to ensure your disaster recovery solutions provide both technical resilience and regulatory compliance. After all, recovering successfully only to face regulatory penalties defeats the purpose of good planning.
Want to learn more about building effective disaster recovery plans? Check out our guide on Cloud-Based Disaster Recovery Plans for additional insights and best practices.
Providers, Cost, Security & Avoiding Lock-In
Let’s talk about something I see businesses struggle with all the time – finding the right balance in their cloud computing and disaster recovery strategy. It’s not just about picking a provider and calling it a day.
Think of your DR strategy like insurance – you want the right coverage without breaking the bank. That’s why many of our clients in Central New Jersey are exploring multi-cloud approaches. By spreading your recovery capabilities across different providers, you’re not putting all your eggs in one basket. This approach helps you avoid getting locked into a single vendor and provides an extra layer of protection if one provider experiences issues.
For some businesses, especially those with limited IT resources, Disaster Recovery as a Service (DRaaS) can be a game-changer. These specialized providers handle the end-to-end recovery process for you, often with stronger guarantees than you’d get from standard cloud services. I’ve seen this work particularly well for our clients in healthcare and financial services who need rock-solid recovery assurances.
One thing that catches many businesses off guard is the true cost of cloud DR. It’s not just about storage – you need to account for compute resources, network traffic, and especially data transfer costs. We always work with our clients to build detailed cost models that consider different disaster scenarios. Trust me, the last thing you want during recovery is a shocking bill!
Speaking of guarantees, take a close look at those performance SLAs. What exactly is your provider promising about availability and recovery time? The best providers back their promises with financial guarantees – if they miss their targets, you get compensated. It won’t fix your downtime issues, but at least it shows they have skin in the game.
Always have an exit strategy. This is something I emphasize with every client. Technology changes, businesses evolve, and you might need to switch providers someday. Avoid proprietary formats or services that create dependency, making it hard to leave if needed.
In today’s threat landscape, security can’t be an afterthought. We recommend implementing zero-trust security principles that verify every access request regardless of source. This is particularly important in hybrid environments where your data might travel between on-premises systems and multiple cloud providers.
The right provider relationship is a partnership, not just a vendor transaction. They should understand what makes your business tick and work alongside you to protect what matters most.
Selecting the Right Partner
Finding the perfect cloud computing and disaster recovery partner feels a bit like dating – compatibility matters! Here’s what to look for in your “perfect match”:
Distance plays a bigger role than many realize. If your business is in Woodbridge or Newark, having your recovery site just a few miles away might seem convenient, but it leaves you vulnerable to regional disasters like major storms or power outages. We typically recommend recovery sites outside the Northeast corridor for our New Jersey clients.
Reliability isn’t just marketing talk – dig into their track record. How have they handled their own outages? Do they communicate transparently when problems occur? One client told me they chose their provider after seeing how honestly the company addressed a service disruption on their status page.
Scalability matters because your business won’t stand still. The provider that perfectly fits your needs today might become a constraint if you double in size next year. This is especially important for our rapidly growing clients in Princeton and Freehold who need room to expand without changing platforms.
Look beyond the flashy logos on a provider’s website and verify their certifications. SOC 2, ISO 27001, and other industry standards provide objective validation of their security and operational practices. If you’re in a regulated industry, make sure they can support your specific compliance requirements.
The support model can make or break your recovery experience. What happens when disaster strikes at 2 AM on a Sunday? Who will answer the phone? What’s their average response time? These questions matter tremendously when you’re in crisis mode.
Finally, don’t underestimate the importance of cultural fit. At Titan Technologies, we pride ourselves on being responsive, proactive, and communicative with our clients. These qualities become even more critical during disaster scenarios when stress is high and time is short.
More info about Backup and DR Solutions
Frequently Asked Questions about Cloud Computing and Disaster Recovery
What’s the difference between backup, DR, and DRaaS?
People often use these terms interchangeably, but they represent different layers of protection for your business.
Think of backup as taking photos of your important documents. If you lose the originals, you still have the pictures. Backups are primarily about preserving copies of your data that you can restore when needed. It’s the foundation of data protection, but it doesn’t address how quickly you can get back to business.
Disaster Recovery (DR) is more comprehensive – it’s like having not just photos of your documents, but a complete plan for rebuilding your office after a fire. DR includes the entire strategy for restoring your technology environment: your data, applications, network connections, and user access. It answers the critical question: “How do we get everything up and running again?”
Disaster Recovery as a Service (DRaaS) is like hiring professional movers who not only help you plan your move but actually pack everything, transport it, and set it all up in your new location. With DRaaS, a specialized provider handles the entire recovery process, from maintaining replicas of your systems to orchestrating the failover when disaster strikes. For many of our clients in places like Edison and Princeton, this “leave it to the experts” approach provides peace of mind without the overhead of managing complex recovery systems themselves.
How often should a cloud DR plan be tested?
If I had a dollar for every time I’ve seen a disaster recovery plan fail during its first real test, I’d be writing this from my beach house! The truth is, untested DR plans are often just wishful thinking.
At a bare minimum, you should perform a comprehensive test annually. But that’s really not enough. Here’s what we recommend to our clients across Central New Jersey:
Mix up your testing approaches throughout the year. Run tabletop exercises quarterly where your team talks through scenarios like “What if our main office lost power for a week?” These discussions often reveal gaps in your planning that aren’t obvious on paper.
Test specific systems every six months by actually recovering them in isolation. This helps verify that your technical procedures work and gives your team practice with the recovery tools.
Conduct a full-scale recovery simulation annually, treating it like a real disaster. This is your dress rehearsal – and just like in theater, dress rehearsals often reveal problems you’ll want to fix before opening night!
Most importantly, test after any significant change to your business or technology. When you upgrade your ERP system or open a new office location, your old recovery procedures may no longer be sufficient.
For our clients in Woodbridge and Newark, we’ve found that implementing some automated testing helps supplement these manual efforts – letting technology verify that basic recovery capabilities remain functional between your more comprehensive tests.
How do RTO and RPO drive cloud DR architecture choices?
Your recovery objectives are like the budget and timeline for building a house – they determine whether you’re building a basic shelter or a hurricane-proof fortress.
When your business needs near-instant recovery (minutes or seconds), you’re in the field of premium cloud computing and disaster recovery solutions:
* You’ll likely need hot DR with systems continuously replicating data
* You might implement active-active configurations where systems run simultaneously in multiple locations
* Your failover will need to be fully automated to meet such aggressive timeframes
* And yes, this approach costs more, just like that hurricane-proof house
For businesses that can tolerate a few hours of downtime (which includes many of our clients in Trenton and New Brunswick), a balanced approach often makes sense:
* Warm DR configurations keep systems in standby mode, ready to activate
* Critical components might use a “pilot light” approach where core systems stay running
* Recovery involves some automation with limited manual steps
* This middle ground provides good protection without breaking the bank
If your business can manage a day or more of recovery time, simpler approaches become viable:
* Cold DR with regular backups might be sufficient
* Recovery procedures can be more manual
* These basic solutions provide essential protection at minimal cost
The beauty of cloud computing and disaster recovery is its flexibility. We often help our clients create tiered recovery plans – applying premium protection to mission-critical systems while using more economical approaches for less urgent needs. This way, you’re investing your protection dollars where they matter most.
These aren’t just technical decisions – they’re business decisions about how much downtime and data loss your organization can tolerate. And they should be revisited regularly as your business evolves.
Conclusion

Let’s face it – disasters don’t schedule appointments. When I sit down with clients across Central New Jersey, I often say that implementing cloud computing and disaster recovery isn’t about pessimism – it’s about practical preparation.
The cloud has truly democratized disaster recovery. Remember when only Fortune 500 companies could afford proper DR solutions? Those days are thankfully behind us. Today, the small medical practice in Newark has access to the same powerful recovery tools as the large manufacturing firm in Elizabeth.
What makes a successful disaster recovery strategy isn’t just technology – it’s alignment with your specific business needs. Think of it like tailoring a suit: one size definitely doesn’t fit all. Your manufacturing operation in Woodbridge has different recovery requirements than a law firm in Princeton. The magic happens when your technical capabilities perfectly match your business priorities.
The path to resilience isn’t complicated, but it does require thoughtful planning. Start by really understanding how downtime affects your specific operations. Define those critical RTO and RPO metrics based on business impact, not technical convenience. Choose the right strategy – whether cold, warm, or hot – that balances protection with budget reality. Implement with careful attention to security and automation. And please, test regularly – a disaster recovery plan that only exists on paper isn’t worth the ink used to print it.
I’ve seen how cloud computing and disaster recovery solutions provide more than just technical protection – they deliver peace of mind. There’s something powerful about knowing your business can weather whatever storm comes your way, whether that’s a ransomware attack, hardware failure, or actual storm (we get our share in New Jersey, don’t we?).
At Titan Technologies, we’ve guided hundreds of businesses through this journey. From healthcare providers needing strict HIPAA compliance to manufacturers requiring rapid system restoration, we understand both the technical nuances and the human concerns behind disaster recovery planning.
The worst time to think about disaster recovery is during a disaster. Like that umbrella you wish you’d brought before the surprise downpour, preparation matters. Your business deserves protection that’s as reliable as it is accessible.
We’re your neighbors here in Central New Jersey, with local expertise and support across Edison, Elizabeth, Lakewood, Newark, Trenton, Princeton, New Brunswick, Matawan, Woodbridge, Freehold, and Red Bank. We understand the unique challenges local businesses face because we face them too.
Don’t leave your business continuity to chance. Reach out today, and let’s build resilience into the very foundation of your operations. Because with the right cloud computing and disaster recovery solution, “disaster” becomes just another word for “minor interruption.”