





Why Every Business Needs a Cloud Based Disaster Recovery Strategy
A cloud based disaster recovery plan is a comprehensive strategy that uses cloud resources to back up and restore critical business data and applications after a disruptive event.
Quick Answer: What is a cloud based disaster recovery plan?
| Component | Description |
|---|---|
| Definition | A set of procedures and technologies that leverage cloud infrastructure to protect and recover business systems after disruptions |
| Primary Goal | Ensure business continuity with minimal downtime |
| Key Metrics | Recovery Time Objective (RTO) and Recovery Point Objective (RPO) |
| Main Approaches | Backup & Restore, Pilot Light, Warm Standby, Multi-site Active/Active |
| Benefits | Cost flexibility, scalability, reduced hardware needs, geographic redundancy |
In today’s digital-first business environment, downtime isn’t just an inconvenience—it’s potentially catastrophic. Just ask Amazon, which reportedly lost $34 million during a mere 63-minute outage. Or consider the sobering statistic that 93% of companies that lost data center access for 10+ days filed for bankruptcy within a year.
The threats are multiplying faster than most businesses can keep up. Ransomware attacks, human errors, hardware failures, and natural disasters can strike without warning. The question isn’t if your systems will face disruption, but when—and how quickly you can recover.
Traditional disaster recovery required significant investments in duplicate hardware, secondary facilities, and complex maintenance. Cloud based disaster recovery changes this equation dramatically. Instead of maintaining idle infrastructure “just in case,” you can leverage on-demand cloud resources, paying only for what you use during normal operations and scaling rapidly when disaster strikes.
For small and medium businesses in particular, cloud DR offers enterprise-grade resilience without enterprise-level costs. With proper planning, your business can maintain operations even when your primary systems fail, protecting both your bottom line and your reputation.
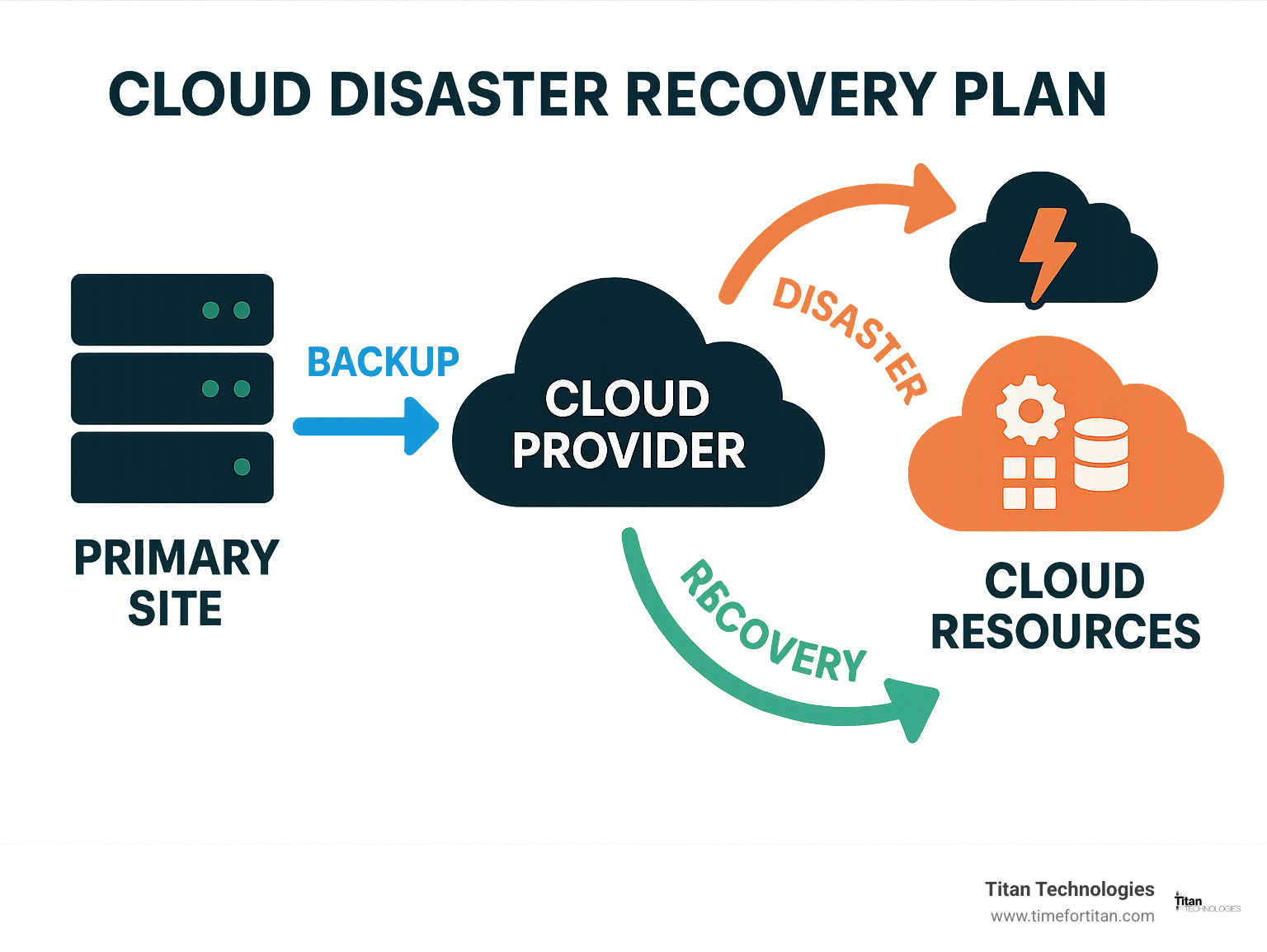
What Is a Cloud Based Disaster Recovery Plan?
A cloud based disaster recovery plan is your business’s safety net in the digital world. Think of it as a well-thought-out playbook that uses cloud resources to protect and recover your critical systems when trouble strikes. Unlike traditional approaches where you’d need duplicate servers sitting idle in a secondary location, cloud DR leverages virtual resources that spring into action only when needed.
“Cloud DR combines services and strategies to store backup data, applications, and resources in cloud storage, enabling quick restoration to resume operations,” as disaster recovery experts often explain. This approach has completely transformed how businesses think about keeping their operations running through unexpected disruptions.
When you implement a cloud based disaster recovery plan, you’re typically setting up:
Virtual machine replicas that maintain copies of your server environments in the cloud, ready to take over when needed. These digital twins of your systems can be spun up within minutes of an outage.
Regular data backups that copy your information to secure cloud storage at frequencies matching your business needs – whether that’s every few hours or every few minutes.
Smart failover processes that can automatically detect when your primary systems are having trouble and smoothly transition operations to your cloud resources without manual intervention.
Clear recovery procedures that guide your team through restoring normal operations once the crisis has passed, ensuring nothing gets overlooked in the heat of the moment.
Regular testing protocols because a recovery plan you haven’t tested is just a theory, not a solution you can count on.
Many businesses implement their cloud based disaster recovery plan through Disaster Recovery as a Service (DRaaS), where specialists handle the technical details. Others prefer building their own capabilities using cloud infrastructure (IaaS) or platform services (PaaS).
One major advantage of cloud DR is geo-redundancy. As industry experts note, “Cloud DR provides geo-redundancy, allowing backup data to be stored across multiple geographical locations, reducing the risk of a single point of failure.” Best practices suggest keeping your DR sites at least 150 miles from your main operations to avoid both locations being affected by the same regional disaster.
Key Metrics: RTO & RPO in a Cloud Based Disaster Recovery Plan
When creating your cloud based disaster recovery plan, two crucial numbers will guide your entire strategy: Recovery Time Objective (RTO) and Recovery Point Objective (RPO). Understanding these concepts isn’t just for IT folks – they translate directly to business impact.
Recovery Time Objective (RTO) answers a simple but critical question: “How long can we afford to be down?” If your business sets an RTO of 4 hours, you’re essentially saying your systems need to be back online within that timeframe to avoid serious consequences to your operations, customers, and bottom line.
Recovery Point Objective (RPO) tackles a different but equally important question: “How much data can we afford to lose?” With an RPO of 1 hour, you’re acknowledging that losing up to an hour’s worth of data changes is tolerable (though not ideal), which means you need to be backing up at least hourly.
Different parts of your business likely need different RTOs and RPOs:
| Workload Type | Typical RTO | Typical RPO | Example |
|---|---|---|---|
| Mission-Critical | Minutes | Seconds to minutes | Payment processing |
| Business-Critical | Hours | Hours | CRM systems |
| Operational | 24 hours | 24 hours | Internal tools |
| Administrative | Days | Days | Historical records |
Setting these targets isn’t about picking arbitrary numbers – it requires honest conversations about:
The financial hit your business takes every hour systems are down
How quickly customer frustration turns into lost business
What regulators expect from your industry
How different systems depend on each other
What’s technically feasible with your resources
“Defining Recovery Point Objective (RPO) and Recovery Time Objective (RTO) for each workload” consistently appears as a critical step in disaster planning. The good news? Cloud-based solutions excel at meeting aggressive RTOs and RPOs through automation and continuous protection that traditional approaches simply can’t match.
Why Your Organization Needs a Cloud Based Disaster Recovery Plan
Let’s face reality – disruptions aren’t a matter of “if” but “when.” According to the Uptime Institute’s 2020 survey, nearly half (44%) of organizations experienced a major outage that hurt their business, with power failures leading the pack of culprits. But that’s just the beginning of the story.
Today’s threat landscape should keep any business leader awake at night:
Cyberattacks have gone mainstream – Ransomware isn’t just targeting giant corporations anymore. Small and mid-sized businesses are increasingly in the crosshairs, with attackers specifically going after backup systems to prevent recovery.
Mother Nature isn’t getting gentler – Climate change has increased both the frequency and severity of weather events that can knock out entire regions, from hurricanes along the coast to flooding in areas that rarely saw such issues before.
People will always be people – Despite our best automation efforts, human errors still cause a surprising number of disasters. One eye-opening study suggests that 94% of disasters are human-made while only 6% are natural.
Everything is connected – As our systems become more intertwined and distributed, the potential points of failure multiply like rabbits.
The consequences of inadequate disaster recovery go far beyond temporary inconvenience. Beyond immediate revenue losses during downtime, you face damaged reputation, customers finding new providers, regulatory penalties, and in worst-case scenarios, the end of your business entirely.
Cloud-based DR offers compelling advantages that traditional approaches simply can’t match:
Pay-as-you-go economics means you’re changing what used to be massive upfront investments into manageable monthly costs. As industry experts note, “cloud-based DR solutions can help organizations save up to 30% on storage costs compared to on-premises solutions.”
Instant scalability ensures you can immediately ramp up resources during an actual disaster without maintaining expensive excess capacity during normal operations.
True geographic diversity leverages cloud providers’ global data center networks, putting significant physical distance between your primary and recovery environments.
Continuous innovation means your DR solution gets better over time as cloud providers roll out new capabilities and improvements.
For businesses in Central New Jersey – including Edison, Elizabeth, Lakewood, Newark, and surrounding communities – the threat landscape is particularly complex. From coastal weather events to power grid vulnerabilities and the region’s concentration of potential cyber targets, having a robust cloud based disaster recovery plan isn’t just a good idea – it’s essential for business survival.
Cloud DR vs. Traditional DR
Understanding the differences between cloud based disaster recovery and traditional approaches helps organizations make informed decisions about their business continuity strategies. Each approach has distinct characteristics that impact cost, complexity, and effectiveness.
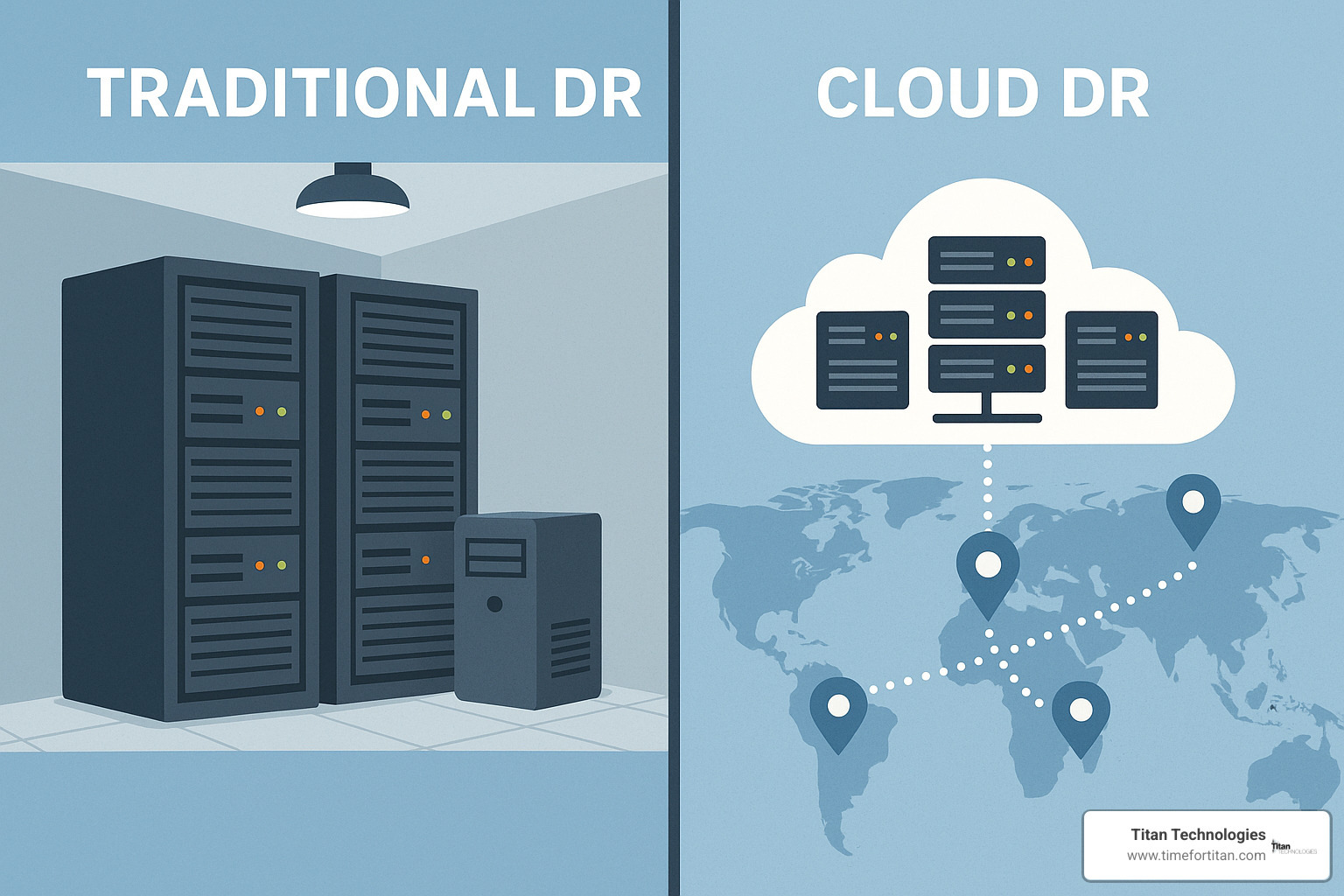
| Factor | Traditional DR | Cloud DR |
|---|---|---|
| Infrastructure | Requires duplicate physical hardware at secondary site | Uses virtual resources provisioned on demand |
| Cost Model | High capital expense (CapEx) for equipment that sits idle most of the time | Operational expense (OpEx) with pay-as-you-go pricing |
| Geographic Flexibility | Limited to specific physical locations | Multiple regions available with global providers |
| Scalability | Fixed capacity based on initial investment | Elastic resources that scale as needed |
| Implementation Time | Weeks to months for hardware procurement and setup | Hours to days for virtual environment configuration |
| Testing Capability | Complex, often disruptive to production | Simplified, isolated testing environments |
| Maintenance Burden | High (hardware, software, facilities) | Reduced (provider handles infrastructure) |
| Recovery Speed | Typically hours to days | Minutes to hours in most cases |
Remember when disaster recovery meant buying a bunch of expensive servers that would sit in a warehouse gathering dust until needed? That’s the traditional DR approach in a nutshell. It’s like buying an entire second car that sits in your garage just in case your main car breaks down.
Traditional disaster recovery requires you to maintain physical infrastructure at a secondary location. You’re paying for hardware, software licenses, data center space, and ongoing maintenance—whether you use it or not. And since you need to plan for your busiest possible day, those resources are typically oversized and underused.
As one of our clients recently joked, “It felt like we were running two IT departments, but only one was actually doing anything useful day-to-day!”
Cloud based disaster recovery flips this model on its head. Instead of physical hardware collecting dust, you store server images and data in the cloud, ready to spring into action when needed. As one industry expert puts it, “Traditional DR uses dedicated standby servers patched to last production configuration, whereas cloud DR uses full server images.” This fundamental difference creates enormous advantages.
The financial change is particularly impressive. Traditional DR requires large upfront capital expenditures regardless of whether you ever activate your recovery environment. Cloud DR shifts to an operational expense model where you primarily pay for what you use. This approach not only preserves capital but also creates predictable monthly costs that scale with your business.
Speed is another game-changer. “Cloud DR can restore systems in seconds compared to hours with traditional methods,” according to recent industry research. For businesses in Edison or Newark, where every minute of downtime means lost revenue, this dramatic improvement can be the difference between a minor hiccup and a major crisis.
Here at Titan Technologies, we’ve guided countless businesses across Central New Jersey away from inflexible traditional DR approaches toward more agile cloud solutions. For our clients in Princeton, New Brunswick, and Matawan, this transition has not only strengthened their recovery capabilities but also freed up valuable resources for strategic growth initiatives.
The agility factor cannot be overstated. When a manufacturing client in Elizabeth needed to quickly scale their disaster recovery capacity before a major product launch, we helped them adjust their cloud DR resources in hours—something that would have taken weeks or months with traditional infrastructure.
Core Strategies for Cloud Disaster Recovery
When it comes to building a cloud based disaster recovery plan, you’ve got options! Think of these strategies like insurance policies – you can choose basic coverage or premium protection, depending on what your business needs and can afford. Let’s explore the approaches that have helped our New Jersey clients sleep better at night.
Backup & Restore Essentials
The backup and restore approach is the simplest way to get started with cloud disaster recovery – it’s like making digital copies of your business and storing them safely in the cloud.
Picture this: your systems are humming along, and in the background, you’re regularly taking snapshots – frozen moments in time of your entire system. These snapshots get stored in the cloud, ready to be restored if trouble strikes. It’s a bit like taking regular photos of a sandcastle before the tide comes in!
Most of our successful backup strategies include regular snapshots, multiple versions (so you’re not stuck if one backup is corrupted), and following the trusty 3-2-1 rule: three copies of your data, on two different types of storage, with one copy offsite in the cloud. We also make sure to regularly test these backups – after all, an untested backup is just a theory!
While this approach is budget-friendly, it does mean longer recovery times. When disaster strikes, you’ll need to set up new infrastructure in the cloud and restore everything before you’re back in business. For many of our clients in Woodbridge and Freehold, we create tiered backup plans where critical systems get more frequent backups than less important ones.
Want to dig deeper into backup solutions? We’ve got you covered: More info about Backup and DR Solutions
Pilot Light & Warm Standby Approaches
If backup and restore feels too slow for your business needs, let’s talk about pilot light and warm standby approaches – these strike a nice balance between cost and speed.
The pilot light approach is named after the small flame that’s always burning in your gas appliance, ready to ignite the main burner when needed. In cloud terms, you maintain a minimal version of your core environment that’s always running. Your databases and critical servers exist in the cloud at a small scale, with your data continuously replicating from your main systems. When trouble hits, you can quickly “turn up the flame” and expand to full capacity.
One of our Princeton clients loves this approach because it dramatically cuts recovery time while keeping monthly cloud costs reasonable. The key is having good automation in place so scaling up happens quickly and reliably when needed.
The warm standby approach takes things a step further. Instead of just a pilot light, you’ve got a scaled-down but fully functional copy of your entire environment running all the time. It’s like having a backup generator that’s already warmed up and running on idle – when the power goes out, it can take the full load almost immediately.
This approach costs more than pilot light during normal operations, but it can get you back in business in minutes rather than hours. For our clients in Trenton who face strict regulations about system availability, this approach hits the sweet spot of recovery speed and cost.
Multi-Site Active/Active Architecture
For businesses where downtime simply isn’t an option (think healthcare providers or financial services), the multi-site active/active approach is the gold standard of cloud based disaster recovery.
This strategy is like having two or more identical restaurants open simultaneously instead of just having a backup kitchen. All locations are serving customers all the time. If one location has a problem, the others simply pick up the slack with minimal disruption.
In tech terms, you’re running identical environments in multiple cloud regions or providers simultaneously. Your applications and data exist in multiple places, with changes synchronizing between them continuously. Smart global load balancers direct users to the healthiest environment automatically.
The beauty of this approach is near-zero downtime and virtually no data loss. When one environment has trouble, traffic automatically flows to the others in seconds. You can even perform maintenance on one environment while the others handle the workload – no late-night maintenance windows needed!
We’ve implemented this architecture for several financial clients in Newark and Elizabeth, where even minutes of downtime could mean significant financial and reputational damage. While it’s the most expensive option, for these businesses, it’s worth every penny for the peace of mind.
At Titan Technologies, we help you choose the right strategy based on your business needs, compliance requirements, and budget. Whether you need basic protection or bulletproof resilience, we’ve got Central New Jersey businesses covered.
Building Your Cloud Based Disaster Recovery Plan Step-by-Step
Creating an effective cloud based disaster recovery plan isn’t just about technology—it’s about thoughtful preparation that protects your business when disaster strikes. Let me walk you through a practical roadmap that’s helped many of our New Jersey clients sleep better at night.

The journey begins with understanding what you’re up against. Every business in Edison, Newark, or Princeton faces unique risks—whether it’s coastal flooding, power outages from winter storms, or the ever-present threat of ransomware. Start by asking: “What could realistically go wrong, and how would it impact our operations?”
Your risk assessment should connect potential threats directly to business outcomes. When that order processing system goes down, are you losing $5,000 per hour? Are regulatory penalties possible? Could customers permanently leave? These answers will drive your entire strategy.
Next, take inventory of what needs protection. Not all systems are created equal—your customer database probably deserves more protection than your office holiday photo archive. I recommend creating clear tiers:
Tier 1 systems are your “can’t live without” applications—the ones where even brief downtime means serious trouble. For many of our Matawan clients, this includes payment processing and core customer-facing systems.
Tier 2 systems are important but can tolerate short outages—think internal CRM or inventory management for many businesses.
Tier 3 and 4 systems progressively tolerate longer recovery times without devastating consequences.
With this understanding, you’re ready to design your recovery architecture. This is where the strategies we discussed earlier come into play—matching each system tier with the appropriate approach. Your mission-critical systems might warrant warm standby configurations, while less urgent systems might use more economical backup and restore approaches.
Don’t underestimate the power of detailed runbooks. During a disaster, clear step-by-step procedures are invaluable. Who makes the call to activate the plan? Which technical steps happen in what order? How do you communicate with customers during the outage? Document everything—the middle of a crisis is not the time for improvisation.
Automation is your best friend in disaster recovery. When properly implemented, automation reduces human error and dramatically speeds recovery. One of our Woodbridge clients recently reduced their recovery time from hours to minutes by automating their failover process. As they told me, “It’s like having an expert technician who never panics, never forgets steps, and works at lightning speed.”
Communication planning deserves special attention. Even the best technical recovery falls flat if customers, employees, and partners are left in the dark. Create templates for different scenarios, establish clear roles for who communicates what, and maintain multiple channels—email might be unavailable during certain outages.
Security cannot be an afterthought. Your disaster recovery environment needs the same rigorous protection as your production systems—perhaps even more, since attackers often target backup systems. Ensure proper access controls, encryption, and network security are built into your recovery architecture from day one.
Finally, an untested plan is just a theory. Schedule regular drills—from tabletop exercises to full-scale failovers. As one of our Trenton clients learned, what looks good on paper doesn’t always work in practice. Their quarterly testing revealed configuration issues that would have prevented successful recovery had they encountered a real disaster.
Component Checklist
A robust cloud based disaster recovery plan requires attention to numerous technical and operational details. While working with businesses across New Jersey, we’ve developed this practical checklist to ensure nothing falls through the cracks.
Data protection forms the foundation of any recovery strategy. Beyond simply scheduling backups, you need to think about how frequently data changes, how it’s replicated to recovery environments, and how it’s protected both during transfer and while at rest. I’ve seen too many organizations find—too late—that their backups were incomplete or corrupted. Regular validation checks are essential.
Infrastructure readiness means having all the necessary components prepared before disaster strikes. This includes creating infrastructure templates that can rapidly deploy your environment, defining how resources will scale during recovery, and ensuring network configurations are properly documented. One Elizabeth client told me, “Having those templates ready to go was like having insurance that actually pays out immediately.”
Access management often gets overlooked until the crisis hits. Who has permission to initiate recovery procedures? How will team members authenticate to recovery systems if your primary authentication system is down? Documenting emergency access procedures ahead of time prevents delays when minutes count.
Compliance requirements don’t disappear during disasters. If you’re subject to HIPAA, PCI, or other regulations, your recovery environment must maintain the same standards as your production systems. This includes considerations like data sovereignty—some data may need to stay within specific geographic boundaries even during recovery.
Operational readiness means your team knows exactly what to do when disaster strikes. Clear roles and responsibilities, established escalation procedures, and defined decision authority prevent the chaos that often accompanies outages. Don’t forget to identify external dependencies—if your recovery plan assumes your internet provider will restore service within four hours, you’d better have that in writing.
At Titan Technologies, we’ve seen how thorough preparation makes the difference between a minor disruption and a major crisis for businesses in Lakewood, Princeton, and throughout Central New Jersey.
More info about Data Protection & Security Controls
Hybrid & Multi-Cloud Design
Many of our clients are finding that a single approach to disaster recovery doesn’t always provide the resilience they need. That’s where hybrid and multi-cloud strategies come into play—combining the best of different worlds to create more robust protection.
A hybrid cloud disaster recovery approach blends on-premises infrastructure with cloud resources. This approach makes perfect sense for many New Jersey businesses that have already invested significantly in their own hardware but want the additional protection cloud offers.
The beauty of hybrid approaches is their flexibility. You can keep sensitive systems on-premises while leveraging the cloud for others. One of our healthcare clients in New Brunswick maintains strict control over patient data on local systems while using cloud resources for everything else. This balances their compliance requirements with the scalability benefits of cloud-based recovery.
Multi-cloud strategies take this concept further by distributing recovery capabilities across multiple cloud providers. I like to think of this as not putting all your eggs in one basket. When Amazon had their major outage last year, organizations with workloads spread across multiple providers barely noticed, while those fully committed to a single provider scrambled.
The benefits go beyond just avoiding outages. Different cloud providers excel at different things. You might find that one provider offers better database services while another has superior networking capabilities. A thoughtful multi-cloud strategy lets you leverage each provider’s strengths.
But I’d be remiss not to mention the challenges. Managing environments across multiple platforms requires sophisticated orchestration tools and broader expertise. Data synchronization becomes more complex, and security controls need careful coordination to ensure consistent protection across environments.
Cost management also requires attention. While multi-cloud can optimize spending, it can also lead to unexpected costs if not carefully managed. One of our Red Bank clients initially found their multi-cloud strategy was actually increasing costs until we helped them implement more effective resource management.
Despite these challenges, for organizations with mission-critical workloads, the resilience benefits often outweigh the added complexity. As one of our Freehold clients put it, “It’s like having multiple insurance policies—it costs a bit more, but I know we’re covered no matter what happens.”
At Titan Technologies, we’ve developed expertise across all major cloud platforms, allowing us to design and implement hybrid and multi-cloud strategies that balance resilience, performance, and cost for businesses throughout Central New Jersey.
More info about Cloud Services
Testing, Maintenance, and Continuous Compliance
Your cloud based disaster recovery plan isn’t a document you create once and file away. It’s a living system that requires ongoing attention to remain effective. Think of it like a fire extinguisher – you hope you’ll never need it, but when you do, it absolutely must work as expected.
Regular Testing Regimen
The hard truth is that untested recovery plans often fail when disaster strikes. That’s why testing isn’t just recommended – it’s essential.
“The first time you test your disaster recovery plan shouldn’t be during an actual disaster,” as one of our clients wisely puts it. We’ve seen companies find critical gaps during testing that would have been devastating in a real emergency.
Start with component testing to verify individual elements like backup restoration or network failover. Then progress to scenario-based tests that simulate specific disasters like ransomware attacks or hardware failures. For critical systems, full-scale exercises that include complete failover and failback processes provide the highest confidence.
Many of our forward-thinking clients in Edison and Newark have acceptd chaos engineering – deliberately introducing controlled failures to strengthen recovery capabilities. Amazon’s famous “Game Days” have popularized this approach, which helps teams build muscle memory for emergency response.
According to research from AWS Resilience Hub, organizations that test regularly are up to 80% more successful in actual recovery situations. We typically recommend quarterly testing for mission-critical systems and at least annual testing for everything else.
Continuous Maintenance
Your business doesn’t stand still, and neither should your recovery plan. As your technology environment evolves, your DR strategy must keep pace.
Schedule quarterly reviews of your DR documentation to ensure it remains accurate. Make DR considerations a standard part of your change management process – that new application or database might introduce dependencies your current plan doesn’t address.
One often overlooked aspect is capacity planning. As your data grows, your recovery infrastructure needs may change. A recovery environment sized for last year’s workloads might buckle under today’s demands.
“We update our runbooks after every significant system change,” shares the IT director at one of our Trenton clients. “It takes discipline, but it’s saved us countless headaches during testing.”
Stay current with your cloud provider’s capabilities, too. New features often enable more efficient or effective recovery options that could improve your RTOs and RPOs while potentially reducing costs.
Compliance Monitoring
For businesses in regulated industries, disaster recovery isn’t just an operational necessity – it’s a compliance requirement. Healthcare organizations must maintain HIPAA compliance, financial institutions face SEC and FINRA requirements, and many businesses must address SOC 2 controls.
Create clear documentation that maps your DR capabilities to specific regulatory requirements. This “compliance matrix” proves invaluable during audits and helps identify gaps before regulators do.
Maintain evidence of your testing and validation activities. Screenshots, logs, and test reports might seem tedious to collect, but they’re your best defense when auditors come calling.
Consider periodic third-party assessments of your DR capabilities. An independent perspective often catches blind spots your team might miss, and external validation carries weight with both regulators and customers.
Maintaining Alignment with RTO/RPO Targets
Business priorities change over time, and your recovery objectives should evolve accordingly. The application that once could tolerate a day of downtime might now be business-critical.
Implement monitoring systems that track key metrics like replication lag and backup completion status. These provide early warning when your actual capabilities drift from your targets.
Visual dashboards make DR readiness visible to stakeholders across the organization. When executives can see at a glance whether recovery capabilities meet business needs, they make better decisions about risk and investment.
Regular SLA reviews ensure your recovery targets still align with business requirements. We’ve worked with clients in Lakewood and Woodbridge who finded their RTOs needed tightening as their business models became more digital and time-sensitive.
At Titan Technologies, we help businesses throughout Central New Jersey implement structured testing programs and maintenance routines that keep their cloud based disaster recovery plans ready for action. Our proactive approach includes regular compliance reviews and alignment checks to ensure your recovery capabilities grow alongside your business.
The most expensive disaster recovery plan is the one that fails when you need it most. Regular testing and maintenance might seem like unnecessary costs when everything’s running smoothly, but they’re your best insurance against catastrophic failure when disaster strikes.
Selecting Providers, Tools, and Architectures
Choosing the right partners and technologies is critical to the success of your cloud based disaster recovery plan. This decision impacts everything from recovery capabilities to ongoing costs and operational complexity.

Evaluating Cloud Providers
When it comes to selecting cloud providers for disaster recovery, location matters—a lot. You’ll want providers with data centers at least 150 miles from your primary location. Think of it as not putting all your eggs in one geographic basket! A hurricane that knocks out power in Newark shouldn’t affect your backup systems in another region.
Service reliability should be at the top of your checklist. Look beyond the marketing promises and dig into the provider’s actual uptime history. A provider promising 99.99% uptime but regularly falling short isn’t a partner you want when disaster strikes.
For businesses in regulated industries, compliance certifications aren’t optional—they’re essential. Before signing any contracts, verify that providers hold relevant certifications like ISO 27001 or SOC 2. Your auditors will thank you later!
The native recovery capabilities of different providers can vary dramatically. Some offer sophisticated, one-click recovery options while others provide more basic tools that require significant configuration. Choose providers whose capabilities align with your technical expertise and recovery needs.
Pay close attention to the cost model, especially data transfer fees during recovery. What seems affordable during normal operations can become surprisingly expensive when you’re transferring terabytes of data during a disaster. One client of ours was shocked by a $15,000 data transfer bill after a major recovery—don’t let that be you!
Selecting DR Tools and Technologies
The right disaster recovery tools can be the difference between a smooth recovery and a stressful scramble. Modern backup and replication solutions do more than just copy data—they maintain application consistency and enable rapid restoration.
Orchestration platforms have transformed disaster recovery from manual, error-prone processes to automated workflows. These tools can orchestrate complex recovery sequences, bringing up applications in the correct order with proper dependencies. It’s like having a digital conductor ensuring every part of your recovery symphony plays at exactly the right moment.
Many organizations overlook the importance of documentation systems until they’re in the middle of a crisis. Having current, accessible runbooks and procedures is invaluable when you’re operating under pressure. As one of our clients put it, “Documentation seemed like a luxury until our primary site flooded and we had to recover with half our team unavailable.”
Testing tools are worth their weight in gold. They allow you to validate your recovery capabilities without disrupting production systems. An untested recovery plan is just a theory—and theories have a way of falling apart when faced with reality.
Architecture Considerations
Your disaster recovery architecture needs to balance recovery capabilities, cost, and complexity. One size definitely doesn’t fit all when it comes to recovery patterns. Your customer database might need a warm standby approach, while your internal knowledge base could be adequately protected with a simple backup/restore strategy.
Network design often gets insufficient attention in DR planning. Even if your applications and data recover perfectly, they’re useless if users can’t connect to them. Plan your network connectivity between primary and recovery environments carefully, considering bandwidth, latency, and security.
The choice between synchronous and asynchronous replication has significant implications for both cost and recovery capabilities. Synchronous replication provides near-zero data loss but requires high-bandwidth, low-latency connections and typically costs more. Asynchronous replication is more forgiving of network limitations but may result in some data loss during a failover.
Security architecture must remain consistent across your environments. A recovery site with weaker security controls than your primary site creates a tempting target for attackers. Maintain identical security standards in both locations—disasters are stressful enough without adding a data breach to the mix!
At Titan Technologies, we maintain partnerships with leading cloud providers and technology vendors, enabling us to design and implement optimal cloud based disaster recovery solutions for businesses across Edison, Elizabeth, and all of Central New Jersey. Our vendor-neutral approach ensures we recommend the best combination of providers and tools for your specific requirements.
Questions to Ask a Prospective Cloud DR Partner
When evaluating potential partners for your cloud based disaster recovery plan, candid conversations can reveal whether a provider is truly equipped to meet your needs or just making sales promises they can’t keep.
Start by discussing recovery guarantees. A good partner should be able to clearly articulate what recovery time (RTO) and recovery point (RPO) they can realistically provide—and be willing to back those promises contractually. Be wary of providers who make vague claims without specifics.
Understanding their technical approach is crucial. Ask about their data replication technologies and how they ensure consistency. A quality partner will explain their methodology in terms you can understand, not hide behind technical jargon.
The testing methodology reveals much about a partner’s confidence in their solution. If they limit your testing opportunities or charge excessive fees for tests, it might indicate they’re not confident in their ability to deliver when it matters. The best partners encourage regular testing and provide comprehensive documentation of results.
The cost structure should be transparent, with no surprises lurking in the fine print. Ask specifically about bandwidth charges during replication and recovery—these can add up quickly. One client told us about a previous provider who charged such high data transfer fees during recovery that they felt “held hostage” during a disaster.
Finally, discuss support levels during both normal operations and disasters. Will you have access to senior engineers during a crisis, or be routed to a standard help desk? How quickly will they respond when systems are down? The answers can make the difference between a minor disruption and a business-threatening disaster.
“For expert guidance, call us” to discuss how Titan Technologies can address these questions and provide a comprehensive cloud based disaster recovery solution custom to your specific needs.
Real-World Success Stories & Lessons Learned
The true test of any cloud based disaster recovery plan comes when disaster actually strikes. Let’s look at some real-world examples that show how effective cloud DR strategies have helped organizations weather various crises—and the valuable lessons they learned along the way.
Manufacturing Firm Survives Ransomware Attack
When a mid-sized manufacturing company in Woodbridge, NJ faced a sophisticated ransomware attack that encrypted their on-premises systems—including their local backups—their cloud-based DR strategy became their lifeline.
“We thought we were prepared with local backups, but the attackers had done their homework,” explains their IT director. “Thankfully, our cloud backups were completely isolated from our main network.”
Within hours, they isolated the infected systems, spun up virtual machines in the cloud using recent snapshots, and restored their critical ERP and production management systems. The entire operation was back up and running within 4 hours, with less than 30 minutes of data loss.
The key lesson? Keep your backups isolated from your main systems to protect against ransomware. By maintaining air-gapped cloud backups that weren’t accessible from their primary network, this company avoided paying a ransom and quickly restored operations with minimal disruption.
Financial Services Firm Maintains Operations During Hurricane
When weather forecasters predicted a major hurricane would hit the New Jersey coast, a financial services firm in Red Bank didn’t wait for disaster to strike—they proactively activated their cloud based disaster recovery plan before the storm made landfall.
“Many companies wait until it’s too late,” notes their operations manager. “We decided to be proactive rather than reactive.”
The team performed a controlled failover to their cloud environment, redirected network traffic using DNS changes, and enabled their staff to work remotely using cloud-based virtual desktops. Throughout the three-day office closure, client services continued without interruption.
The valuable lesson here? Proactive failover before a predicted disaster can significantly reduce risk. By activating their DR plan ahead of the hurricane, this firm avoided the chaos of an emergency failover and ensured smooth business continuity when their competitors were scrambling.
Healthcare Provider Addresses Regulatory Audit with Cloud DR
Regulatory compliance is a major concern for healthcare organizations. When a healthcare provider in Princeton faced a detailed regulatory audit scrutinizing their disaster recovery capabilities, their comprehensive cloud based disaster recovery plan became their ace in the hole.
Their cloud-based approach helped them demonstrate compliance with HIPAA contingency planning requirements, provide evidence of regular DR testing, show clear RPO/RTO definitions aligned with patient care needs, and document robust encryption and access controls for protected health information.
“The auditors were impressed by both our thoroughness and our cost efficiency,” says their compliance officer. The key insight? Cloud DR can help organizations save up to 30% on storage costs compared to on-premises solutions while still meeting stringent compliance requirements. This provider maintained rock-solid compliance while optimizing their IT spending—a win-win scenario.

E-Commerce Business Scales During Peak Season
For an e-commerce company in Edison, disaster struck at the worst possible time—during their busiest sales period of the year. When a critical hardware failure occurred, their cloud DR strategy kicked in automatically.
Their monitoring systems detected the failure immediately, triggering an automated failover to their warm standby environment. Even more impressively, their cloud resources automatically scaled to handle the holiday traffic surge, allowing them to process orders without customers noticing any disruption.
“What could have been a catastrophic loss of revenue became a non-event for our customers,” their CTO explains with relief. The crucial lesson? Leveraging auto-scaling to right-size resources during DR events allows organizations to maintain performance even during peak demand periods while controlling costs during normal operations.
These success stories demonstrate that a well-designed and thoroughly tested cloud based disaster recovery plan can make the difference between a minor hiccup and a major business crisis. At Titan Technologies, we’ve helped numerous businesses across Central New Jersey implement similar strategies custom to their specific needs and risk profiles.
Whether you’re concerned about ransomware, natural disasters, hardware failures, or regulatory compliance, we can help you build resilience into your operations with a cloud-based approach that fits your business requirements and budget.
Frequently Asked Questions about Cloud Based Disaster Recovery Plans
How often should we test our cloud DR plan?
Testing your cloud based disaster recovery plan isn’t just a box-checking exercise—it’s your insurance policy that everything will work when disaster strikes. Most organizations should test at least annually, but that’s really the bare minimum for peace of mind.
For a more robust approach, consider how critical each system is to your business operations. Your most critical systems—the ones that would cause immediate pain if they went down—should undergo quarterly recovery tests. Important but less urgent systems might need semi-annual testing, while your less critical systems can usually get by with annual validation.
Significant changes to your environment should trigger additional testing too. As one of our disaster recovery specialists often tells clients, “If you’ve made major changes to your infrastructure or applications, your previous test results are already outdated.”
Different testing approaches serve different purposes in your overall strategy. Table-top exercises help train your team and validate procedures without disrupting systems. Component testing lets you verify specific recovery elements work correctly. And full-scale simulations—while more resource-intensive—provide the most comprehensive validation that your entire recovery process works end-to-end.
Here in New Jersey, we’ve helped businesses from Lakewood to Newark implement testing schedules that strike the right balance between thoroughness and minimal disruption to daily operations.
What is the difference between failover and disaster recovery?
Though people sometimes use these terms interchangeably, failover and disaster recovery actually serve distinct purposes in your business continuity toolkit.
Failover is like having an understudy ready to step in when the lead actor can’t perform. It’s the automatic or manual switching to a redundant system when something fails, typically happening within the same data center. Failovers are designed for speed—measured in seconds or minutes—and often handle specific components rather than entire environments. They’re your first line of defense against brief outages and are usually automated through monitoring tools that can detect and respond to problems almost instantly.
Disaster Recovery, on the other hand, is more like having an entire backup theater company ready to perform if the main venue becomes unusable. It’s a comprehensive strategy for recovering your entire IT environment after a major disruption like a flood, fire, or widespread system failure. It typically involves geographically separate recovery sites and may take longer to implement—minutes to hours—but provides protection against much larger threats.
As one of our cloud architects explains to clients, “Failover keeps you running during a hiccup. Disaster recovery gets you back in business after a hurricane.”
In a well-designed cloud based disaster recovery plan, failover mechanisms often play an important role, particularly for systems where every minute of downtime hurts your bottom line. But they’re just one component of your broader recovery strategy.
Can hybrid or multi-cloud setups improve resilience?
Absolutely! When thoughtfully implemented, hybrid and multi-cloud approaches can significantly boost the resilience of your cloud based disaster recovery plan—though they do come with some complexity trade-offs.
A hybrid cloud approach gives you the best of both worlds. You can leverage your existing on-premises infrastructure while gaining cloud benefits, allowing for a more gradual transition to cloud-based DR. Many of our clients in Central New Jersey appreciate how this approach lets them keep sensitive data local when required by regulations while still benefiting from cloud scalability and geographic distribution. It essentially creates multiple paths to recovery, giving you more options when responding to different disaster scenarios.
Taking this a step further, a multi-cloud strategy spreads your eggs across several baskets. By using services from multiple cloud providers, you eliminate dependency on any single vendor—if AWS has an outage, perhaps your Microsoft Azure resources are unaffected. You also gain access to specialized capabilities from different providers and a wider range of data center locations for geographic diversity.
“I sleep better knowing we’re not tied to just one cloud provider,” a healthcare client in Princeton told us recently. “Our multi-cloud approach means we have backup plans for our backup plans.”
Of course, these approaches do introduce additional considerations. You’ll need to manage data synchronization between environments, maintain consistent security controls across platforms, and handle more complex networking. Your team may need broader skills, and you’ll require more sophisticated orchestration tools.
At Titan Technologies, we’ve guided numerous businesses across Matawan, Freehold, and throughout Central New Jersey in implementing hybrid and multi-cloud strategies that strike the right balance—maximizing resilience while keeping complexity manageable. The peace of mind our clients gain from these robust solutions makes the additional planning well worth the effort.
Conclusion
In today’s digital business landscape, a robust cloud based disaster recovery plan isn’t just an IT consideration—it’s a business imperative. The statistics paint a sobering picture: 93% of companies that lost data center access for 10+ days filed for bankruptcy within a year. With threats multiplying from ransomware attacks to natural disasters, the question isn’t if your organization will face disruption, but when—and how quickly you can recover.
Cloud-based disaster recovery has revolutionized what’s possible for businesses of all sizes. Gone are the days when organizations needed massive capital investments in duplicate infrastructure that sits idle most of the time. Instead, the cloud offers flexible, scalable resources that can be deployed on demand, dramatically reducing costs while improving recovery capabilities.
Throughout this guide, we’ve walked through the essential components of an effective cloud based disaster recovery plan. We’ve explored how understanding RTO and RPO metrics defines what success looks like for your recovery efforts. We’ve compared traditional approaches with modern cloud solutions to help you identify the right fit for your unique situation. From simple backup-and-restore strategies to sophisticated multi-site architectures, we’ve examined the options available to protect your business.
The step-by-step planning process we’ve outlined helps you build a recovery strategy custom to your specific business needs—not a one-size-fits-all approach that leaves gaps in your protection. We’ve emphasized that rigorous testing and maintenance aren’t optional extras but essential components of a plan that will actually work when disaster strikes.
The real-world success stories we’ve shared aren’t theoretical—they represent actual businesses that weathered severe disruptions with minimal impact because they had well-designed cloud DR plans in place. These organizations protected not just their operations but their reputations and customer relationships.
At Titan Technologies, we’ve guided countless businesses across Central New Jersey—from Edison to Princeton, Elizabeth to Red Bank—through implementing cloud based disaster recovery plans that provide both peace of mind and tangible business protection. Our experienced team understands the unique challenges facing businesses in our region and can help you steer every step of the process, from initial assessment to ongoing testing and optimization.
Don’t wait for disaster to strike before taking action. That’s like waiting until your house is on fire to buy insurance. Contact Titan Technologies today to begin developing or enhancing your cloud based disaster recovery plan. Our friendly, professional team is ready to provide the fast, reliable support we’re known for—backed by our 100% satisfaction guarantee. Together, we’ll ensure your business remains resilient no matter what challenges come your way.