





Why AWS DR Solutions Are Critical for Business Continuity
AWS DR solutions provide the backbone for keeping your business running when disaster strikes. Whether it’s a ransomware attack, natural disaster, or simple hardware failure, having the right disaster recovery strategy can mean the difference between a minor hiccup and a business-ending catastrophe.
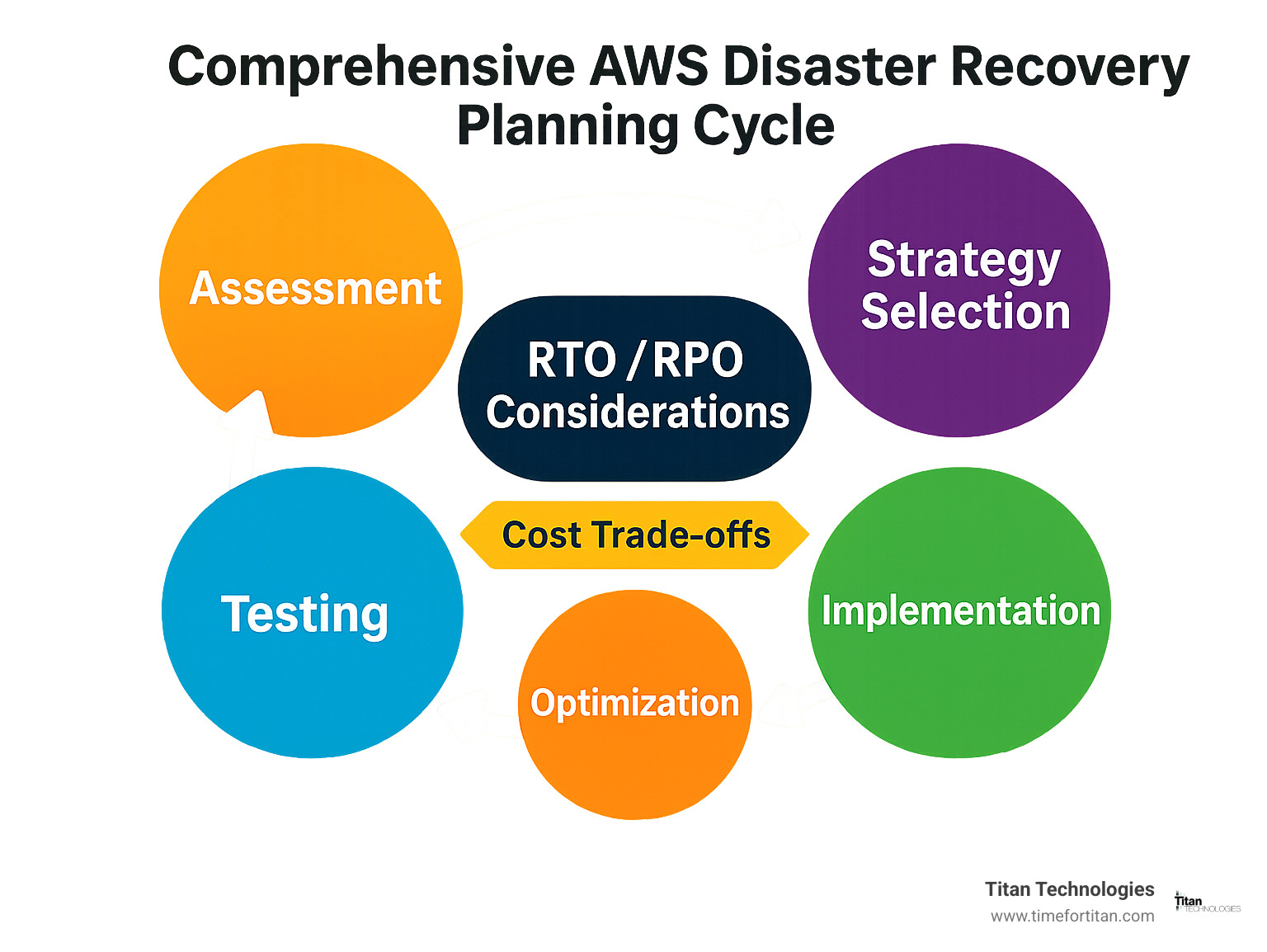
Four main AWS DR strategies are available:
– Backup & Restore – Lowest cost, highest recovery time
– Pilot Light – Minimal always-on infrastructure in standby region
– Warm Standby – Scaled-down version running continuously
– Multi-Site Active/Active – Full production capacity across regions
Each strategy offers different Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs). RTO measures how long you can afford to be down, while RPO measures how much data you can afford to lose.
The stakes are real. No industry is immune to disasters, and AWS Elastic Disaster Recovery can achieve RPOs of seconds and RTOs of minutes when properly implemented. Companies like Tyler Technologies have seen 12x faster recovery of mission-critical workloads, while Olli Salumeria saved 80% on disaster recovery costs for their SAP infrastructure.
Your choice depends on three key factors: how much downtime you can tolerate, how much data loss is acceptable, and what you’re willing to spend. A simple backup strategy might work for non-critical systems, but customer-facing applications often need more robust solutions.
Common aws dr solutions vocab:
– backup and dr solutions
– cloud based disaster recovery plan
– disaster recovery plan example
Core Concepts: RTO, RPO & Why Disaster Recovery Matters
When your business systems go down, every minute counts. That’s why understanding Recovery Time Objective (RTO) and Recovery Point Objective (RPO) isn’t just technical homework—it’s the difference between a minor inconvenience and a business crisis.
Think of these metrics as your disaster recovery GPS. Without them, you’re driving blind when things go wrong. Scientific research on recovery objectives confirms what we see every day: businesses with clear RTO and RPO targets bounce back faster and lose less data when disaster strikes.
The numbers tell a sobering story. The average cost of downtime varies dramatically by industry, but even small businesses can face thousands of dollars in losses per hour. For a medical practice in Central New Jersey, losing access to patient records for even 30 minutes can mean canceled appointments and frustrated patients. For a manufacturing company, a few hours of downtime might halt an entire production line.
Setting Measurable Objectives
Recovery Time Objective (RTO) answers a simple question: How long can your business survive without its critical systems? If your e-commerce website starts losing customers after 15 minutes of downtime, your RTO is 15 minutes. If your accounting firm can manage with email being down for half a day, your RTO might be 12 hours.
Recovery Point Objective (RPO) tackles a different problem: How much data can you afford to lose? This isn’t about storage space—it’s about time. If you back up your customer database every hour, you could lose up to an hour’s worth of new orders, updates, and transactions. For some businesses, that’s acceptable. For others, it’s catastrophic.
Here’s where many businesses trip up: their aws dr solutions don’t align with their Service Level Agreements. We’ve worked with companies that promised customers 99.9% uptime but had backup strategies that couldn’t deliver anything close to that. The math has to work, or your reputation suffers.
Mapping Risk to Impact
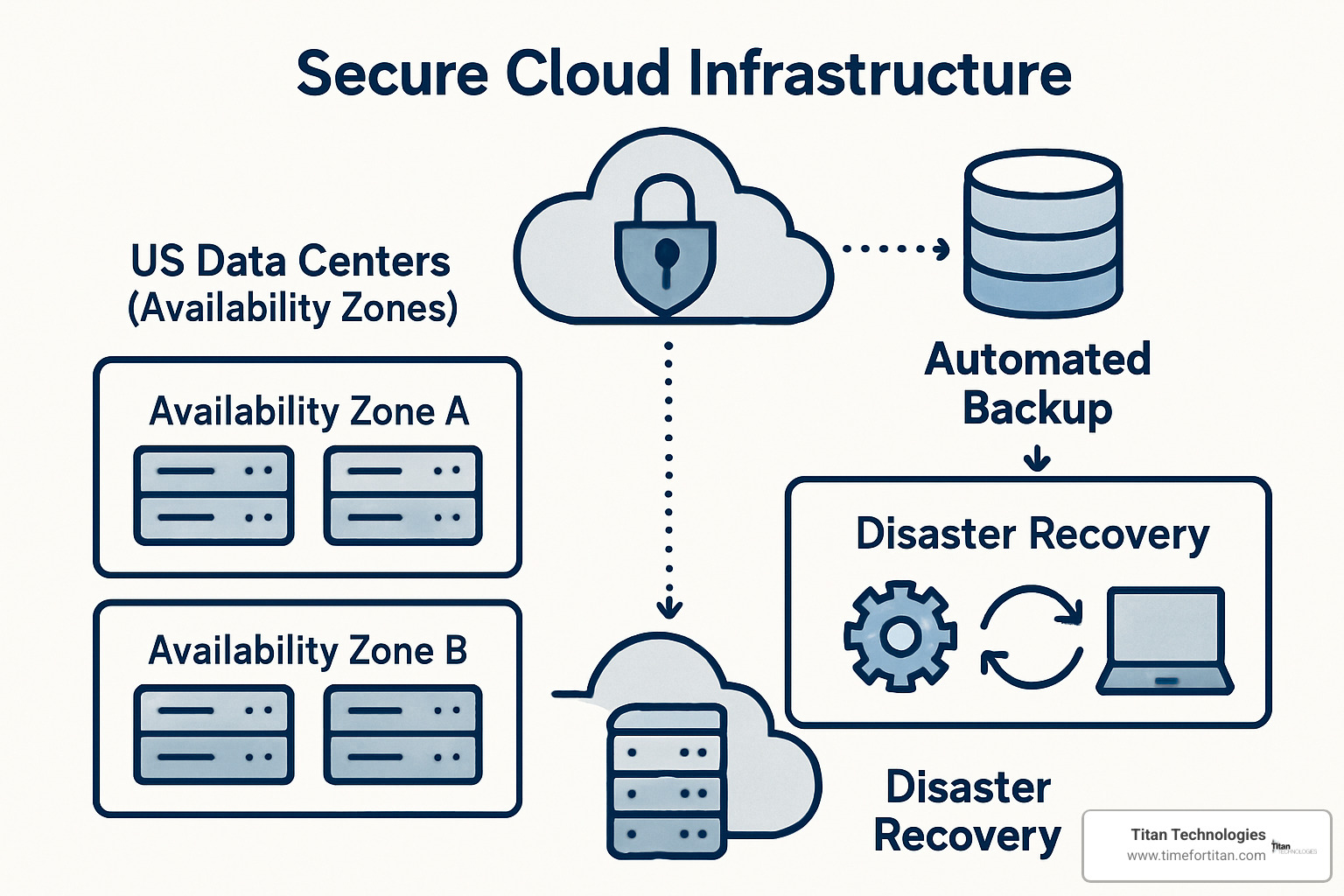
Not all disasters are created equal, and your response shouldn’t be either. A single Availability Zone failure in AWS typically affects one data center and resolves within hours. It’s inconvenient but manageable for most businesses.
A regional outage is a different beast entirely. When an entire AWS region goes dark, you need cross-region failover capabilities. These events are rare, but they can cripple businesses that aren’t prepared.
Human error causes about 70% of all outages. Someone accidentally deletes a database, misconfigures a server, or pushes bad code to production. These scenarios need point-in-time recovery options that let you roll back to before the mistake happened.
Ransomware attacks represent the fastest-growing threat. When cybercriminals encrypt your data and demand payment, your only clean path forward is restoring from uncompromised backups. This is where having geographically separated, immutable backups becomes critical.
The key insight? Your disaster recovery investment should match your actual risk profile. A small accounting practice in Freehold doesn’t need the same multi-region architecture as a financial services firm handling millions in daily transactions. But both need strategies that align with their specific vulnerabilities and recovery requirements.
Comparing AWS DR Strategies: Backup & Restore, Pilot Light, Warm Standby, Multi-Site Active/Active
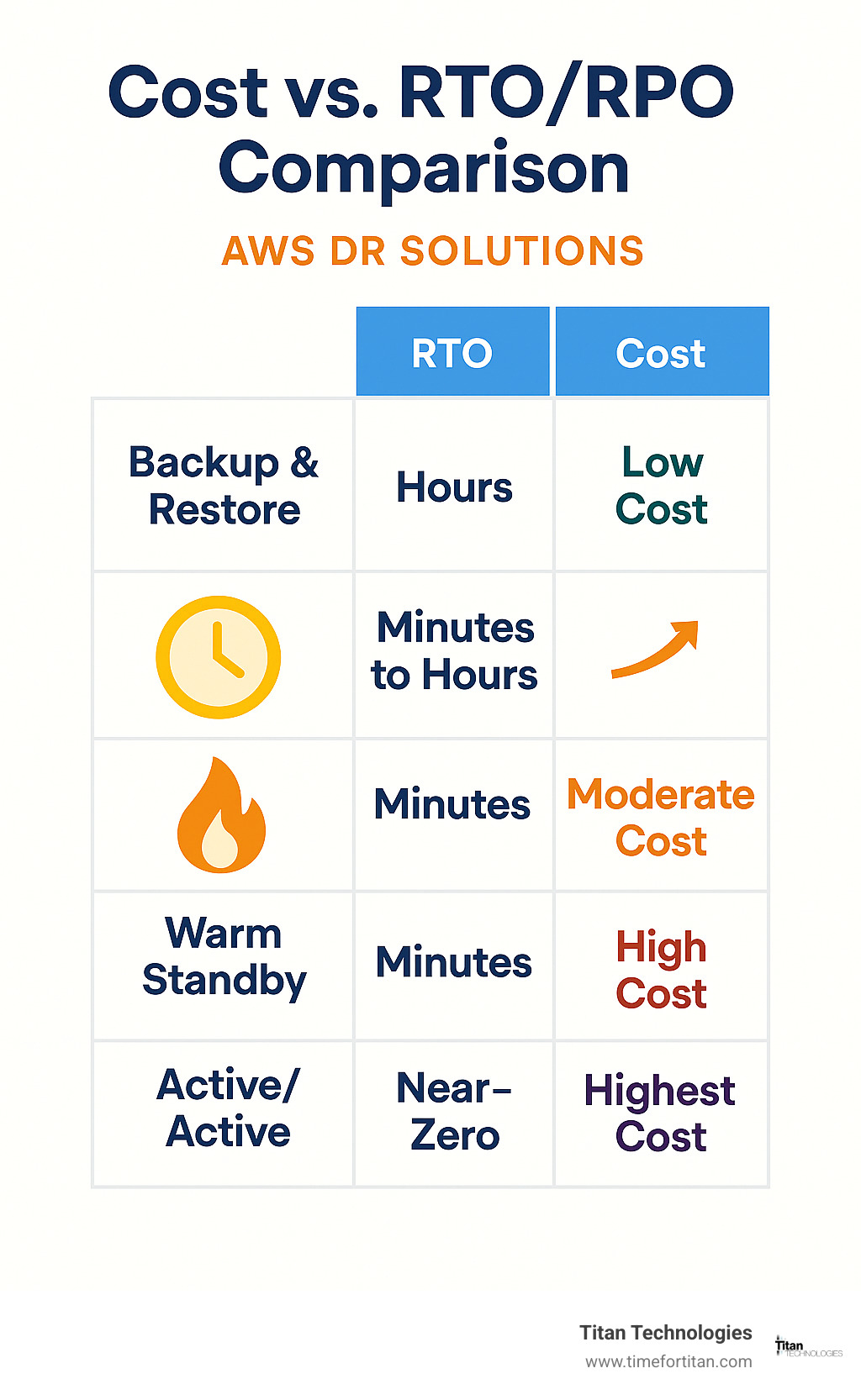
The four AWS DR solutions exist on a spectrum from low-cost/high-RTO to high-cost/low-RTO. There’s no one-size-fits-all solution—the right choice depends on your specific business requirements and budget constraints.
Backup and Restore offers the most cost-effective approach but comes with the longest recovery times. Pilot Light strikes a balance between cost and recovery speed by keeping core services ready in a standby region. Warm Standby maintains a scaled-down version of your environment that can quickly scale up. Multi-Site Active/Active provides the fastest recovery but at the highest cost.
Backup & Restore Deep Dive
The backup and restore strategy is like having a detailed blueprint of your house and all your belongings stored in a safe deposit box. If your house burns down, you can rebuild everything, but it takes time.
AWS Backup provides a centralized service for backing up data across AWS services. Combined with Amazon S3’s 99.999999999% (11 9’s) durability and S3 Glacier for long-term archival, you get incredibly reliable data protection at low cost.
Key components include:
– S3 Cross-Region Replication for automatic backup copying
– Versioning to protect against accidental deletions
– Infrastructure as Code (IaC) using CloudFormation for rapid environment recreation
– Lifecycle policies to automatically move old backups to cheaper storage tiers
The trade-off is time. While you might save 85% on storage costs compared to keeping warm standby infrastructure running, your RTO could be hours or even days depending on how much infrastructure needs rebuilding.
For detailed implementation guidance, check out our comprehensive Backup and DR Solutions guide.
Pilot Light Essentials
Think of pilot light like keeping a furnace pilot flame burning—it’s not heating the house, but it’s ready to ignite the full system quickly. This strategy keeps your most critical core services running in a secondary AWS region with minimal compute resources.
Aurora Global Database is perfect for pilot light setups. It replicates your primary database to a secondary region with typically less than one second of replication lag. When disaster strikes, you can promote the secondary cluster to primary in under one minute.
CloudFormation templates define your full infrastructure as code, allowing rapid deployment of compute resources when needed. The beauty is you’re only paying for data storage and minimal compute until you actually need to scale up.
Warm Standby Blueprint
Warm standby runs a scaled-down version of your production environment continuously. It’s like having a smaller backup generator that’s always running and ready to take full load when needed.
This approach uses:
– Scaled-down EC2 instances handling minimal traffic
– Auto Scaling groups configured to rapidly scale to production capacity
– Elastic Load Balancers ready to distribute traffic
– Route 53 health checks for automatic DNS failover
The advantage is much faster recovery times—often minutes instead of hours. The downside is higher ongoing costs since you’re running actual infrastructure 24/7.
Multi-Site Active/Active Architecture
Active/active is the gold standard for mission-critical applications that can’t afford any downtime. Both sites run production traffic simultaneously, so if one fails, the other seamlessly takes over.
Key technologies include:
– DynamoDB Global Tables for multi-region write replication
– AWS Global Accelerator for intelligent traffic routing
– Conflict resolution strategies for handling simultaneous writes
– Real-time monitoring across all regions
This approach can achieve near-zero RTO but comes with the highest complexity and cost. It’s typically reserved for applications where even minutes of downtime cost thousands of dollars.
Implementing AWS DR Solutions End-to-End
Moving from planning to actual implementation is where the rubber meets the road with AWS DR solutions. We’ve walked hundreds of businesses through this process, and the good news is that AWS has made it significantly easier than it used to be.
AWS Elastic Disaster Recovery (AWS DRS) has become our top recommendation for most clients because it takes the complexity out of the equation. Think of it as having a professional pit crew for your disaster recovery—they handle all the technical details while you focus on running your business.
The service works by continuously replicating your servers to a low-cost staging area in AWS. When disaster strikes, it launches recovery instances within minutes using either the most recent data or a specific point-in-time snapshot. We’ve seen it protect up to 3,000 servers while achieving RPOs of seconds and RTOs of minutes.
Beyond AWS DRS, your implementation toolkit includes AWS Resilience Hub for continuously validating that you’re meeting your RTO and RPO targets. AWS DataSync handles large-scale data migration and ongoing replication beautifully. For coordinated multi-region failovers, Application Recovery Controller (ARC) orchestrates everything smoothly. AWS Config keeps track of configuration changes and helps maintain compliance.
Ready to get started? You can Get started with Elastic Disaster Recovery through the AWS console and begin protecting your critical workloads immediately. The setup wizard walks you through everything step by step.
Choosing AWS DR Solutions for Your Workload
Here’s the truth: not every application needs the same level of protection. Your company website can probably handle a few hours of downtime, but your customer database? That’s a different story entirely.
We use a practical assessment approach with businesses throughout Central New Jersey to match the right strategy to each workload. The process starts with understanding what downtime actually costs your business—and we mean real dollars, not just theoretical impact.
The key questions we ask include understanding the financial impact of each hour of downtime, how much data loss your business can actually tolerate, and whether you have regulatory compliance requirements to consider. We also look at your current hybrid on-premises infrastructure and existing backup processes.
For businesses with compliance needs, certain industries require specific recovery capabilities. Financial services companies often need more robust solutions than retail businesses. Healthcare organizations have strict HIPAA requirements that influence their DR strategy.
Hybrid cloud considerations add another layer of complexity. If you’re running some workloads on-premises and others in AWS, your DR strategy needs to account for both environments. We’ve helped businesses in Edison and Elizabeth steer these mixed environments successfully.
The cost trade-offs become crystal clear when you quantify the business impact. When an hour of downtime costs tens of thousands of dollars, investing in warm standby infrastructure that runs continuously suddenly makes perfect financial sense.
Automating & Testing AWS DR Solutions
Manual disaster recovery is like trying to change a tire during a thunderstorm—everything that can go wrong will go wrong, and stress makes it ten times harder. That’s why automation isn’t just nice to have; it’s absolutely essential.
CloudFormation and AWS CDK let you define your entire infrastructure as code. When disaster strikes, you’re not frantically trying to remember which security groups to create or which subnets to configure. Everything deploys automatically, exactly the way it should.
AWS Lambda functions can trigger automated responses to specific events, while Step Functions orchestrate complex multi-step recovery workflows. EventBridge monitors for failure conditions and kicks off recovery procedures before you even know there’s a problem.
The real magic happens when these services work together. We’ve built systems that detect failures, automatically failover to backup regions, update DNS records, and send notifications—all without human intervention.
Testing deserves special attention because it’s often the most neglected part of DR planning. AWS DRS allows non-disruptive testing, meaning you can validate your procedures without impacting production systems. We recommend quarterly full DR tests and monthly targeted drills for critical systems.
The AWS Well-Architected Lab provides excellent hands-on exercises for testing backup and restore procedures. It’s like a flight simulator for disaster recovery—you get to practice in a safe environment.
Cost Optimization of AWS DR Solutions
Let’s be honest: DR costs can get out of hand quickly if you’re not careful. The trick is paying for protection, not waste. We’ve seen businesses cut their DR costs by 40-60% while actually improving their recovery capabilities.
Storage optimization starts with intelligent tiering strategies. S3 Intelligent-Tiering automatically optimizes costs by moving data between access tiers based on usage patterns. For backups you rarely access, S3 Glacier and Deep Archive offer massive savings. Lifecycle policies automatically delete old snapshots so you’re not paying to store ancient backups forever.
Don’t overlook EBS snapshot compression and incremental backups—they can significantly reduce storage costs while maintaining full protection.
Compute optimization requires right-sizing your standby instances based on actual recovery needs, not worst-case scenarios. Spot instances work great for non-critical DR testing, offering up to 90% savings. Auto Scaling prevents over-provisioning by scaling resources only when needed.
One trick we use with clients in Woodbridge and Matawan is scheduling non-production DR environments to run only during business hours. Why pay for compute resources overnight and weekends when you’re not testing?
The key insight is that encryption and monitoring don’t have to break the bank. AWS provides cost-effective options for both that integrate seamlessly with your DR strategy.
Frequently Asked Questions about AWS DR Solutions
When we help businesses across Central New Jersey implement aws dr solutions, these three questions come up again and again. Let’s tackle them with the straightforward answers you need.
How often should I test my AWS DR plan?
Here’s the honest truth: most businesses don’t test their DR plans nearly enough. We recommend testing at least twice per year for most companies, but monthly targeted tests for anything mission-critical. Think of it like fire drills—you don’t want the first time you use the emergency exit to be during an actual emergency.
The testing frequency really depends on what you’re protecting. Financial services companies often face regulatory requirements for quarterly full tests. Healthcare organizations typically get away with annual testing, but they need to be thorough about it. E-commerce businesses? They should definitely test before peak seasons like Black Friday—imagine your online store going down during your biggest sales weekend.
The good news is that AWS DRS makes testing much less painful with non-disruptive drills. You can validate your recovery procedures without affecting production systems or stopping ongoing replication. It’s like practicing your presentation without the audience watching.
What AWS services automate failover and failback?
Nobody wants to be manually switching systems over at 2 AM during a crisis. Fortunately, AWS offers several services that handle the heavy lifting automatically.
Route 53 provides DNS-based failover with health checks that automatically redirect traffic to healthy endpoints when problems are detected. AWS Global Accelerator takes this a step further with application-layer failover that converges faster than traditional DNS switching.
For databases, Amazon RDS Multi-AZ automatically fails over to a standby instance within the same region when issues arise. Aurora Global Database can promote a secondary region to primary in under one minute—pretty impressive when you consider the alternative of manually rebuilding everything.
Application Load Balancers automatically route traffic away from unhealthy targets, while Auto Scaling launches replacement instances when failures are detected. The key is designing your architecture to leverage these automated capabilities rather than relying on manual intervention during high-stress situations. Trust us, you don’t want to be the person frantically clicking buttons while the CEO is breathing down your neck.
How do RTO and RPO influence my DR cost?
This is where the rubber meets the road. Your RTO and RPO requirements directly drive your DR costs—the tighter your objectives, the more expensive your solution needs to be. It’s simple physics: faster recovery costs more money.
For RPO requirements, think of it this way: if you can live with losing 24 hours of data, daily backups might suffice and cost very little. But if you can only afford to lose an hour’s worth of data, you’ll need hourly backups or database replication, which costs more. Need RPO of minutes? Now you’re looking at continuous replication. Want RPO of seconds? That requires synchronous replication across regions, and your wallet will feel it.
RTO follows the same pattern. If you can wait days to recover, backup and restore from archive storage is cheapest. Need recovery in hours? You’ll want backup and restore with pre-staged infrastructure. Minutes? You’re looking at warm standby or pilot light solutions. Seconds? That’s active/active multi-region deployment territory—the most expensive option.
The trick is finding that sweet spot where your DR investment matches your actual business risk, not your worst-case fears. We work with clients in Edison and Elizabeth to figure out what they really need versus what they think they need. Sometimes a $500 monthly pilot light setup makes more sense than a $5,000 active/active configuration, even if the latter sounds more impressive.
Conclusion
Building a resilient business isn’t just about having great products or services—it’s about making sure you can deliver them even when everything goes wrong. AWS DR solutions give you that resilience, offering everything from simple backup strategies to sophisticated multi-region deployments that keep your business running no matter what.
The beauty of AWS disaster recovery lies in its flexibility. You don’t need to choose between breaking your budget and protecting your business. Whether you’re a small accounting firm in Freehold that needs basic backup protection or a growing tech company in Princeton requiring near-zero downtime, there’s a solution that fits.
Remember the fundamentals: start with clear RTO and RPO objectives based on real business impact, not worst-case scenarios. A manufacturing company that can afford a few hours of downtime doesn’t need the same expensive active/active setup as a financial services firm where every minute costs thousands.
Automation is your friend during disasters. When systems are failing and stress levels are high, you want your recovery procedures to run themselves. CloudFormation templates, Lambda functions, and AWS DRS take the guesswork out of recovery.
Testing isn’t optional—it’s insurance for your insurance. We’ve seen too many businesses find their DR plans don’t work during actual disasters. Regular testing with AWS’s non-disruptive tools means you’ll know your systems work before you desperately need them.
At Titan Technologies, we’ve walked this journey with businesses across Central New Jersey. From helping a family restaurant in Woodbridge protect their online ordering system to implementing enterprise-grade DR for manufacturing companies in Edison, we’ve seen how the right AWS DR solutions transform business confidence.
Our approach is simple: understand your business first, then build technology around it. We don’t push expensive solutions you don’t need, and we don’t leave you vulnerable with inadequate protection. Our 100% satisfaction guarantee means we’re not happy unless your business is truly protected.
Disasters don’t send calendar invites. That ransomware attack, power outage, or natural disaster won’t wait for a convenient time. The businesses that survive and thrive are the ones that prepare before they need to.
Ready to build real resilience into your business? Our comprehensive Business Disaster Recovery (BDR) services take the complexity out of implementing AWS DR solutions. Let’s work together to create a disaster recovery strategy that protects your business without keeping you awake at night worrying about costs.